強化學習簡介(2)--價值函數和Q函數
期望回饋
本簡介基於中興大學林長鋆教授在中華開放教育平台開設的強化學習課程整理而成。課程網址在此,歡迎有興趣的朋友點擊連結。
價值函數和Q函數,指的都是在特定策略下,能得到回饋的期望值。因為機率性環境或策略,採取行動或狀態的變化並非每次都一致,取期望值是比較有參考性的作法。
價值函數
又稱為狀態價值函數,表示在單一回合裡,採取策略在狀態的期望回饋。回饋,指的是當前回合,從當前狀態開始,到本回合結束狀態的獎勵總和。這邊簡化,先不加入折扣因子。
確定性策略
價值函數即為回饋函數,。因為每個狀態都固定只會採取一種行動,也固定只會得到一種獎勵,所以回饋也是固定的。
機率性策略
價值函數為回饋函數的期望值,
舉例
確定性策略
例如在某回合使用策略π,經過四個狀態,A、D、E、F,總共得到三個獎勵1、1、-1
- 在狀態A獲得的回饋是1+1-1=1
- 在狀態D,回饋是1-1=0,因為狀態A不在範圍內(過了當前狀態)
- 狀態E是-1,狀態F也是0(沒有價值)
隨機性策略
例如在某回合,於狀態E,有0.3機率()採取行動至狀態D,並接著100%轉移至狀態A、B,其獎勵依序為1、1、-1;有0.7機率()轉移至狀態H,並接著100%轉移至狀態I,其獎勵為1、1,畫成流程圖如下:
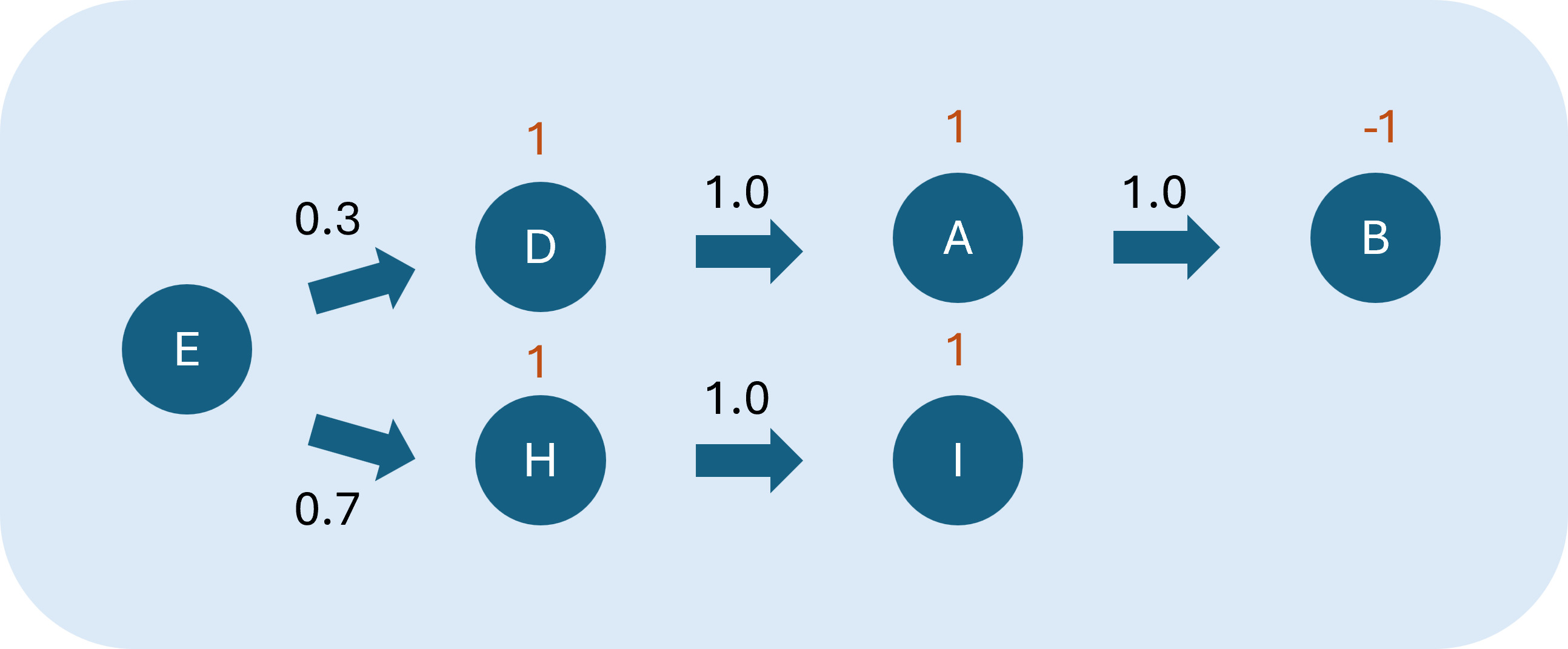
- 的回饋是1+1-1=1,的回饋是1+1=2
- 機率加權之和為1×0.3+2×0.7=1.7
最佳價值函數(optimal value function,)
從不同策略取得的價值中,取最大者。例如,圖1.為策略1()的價值,而策略2()則為圖2:
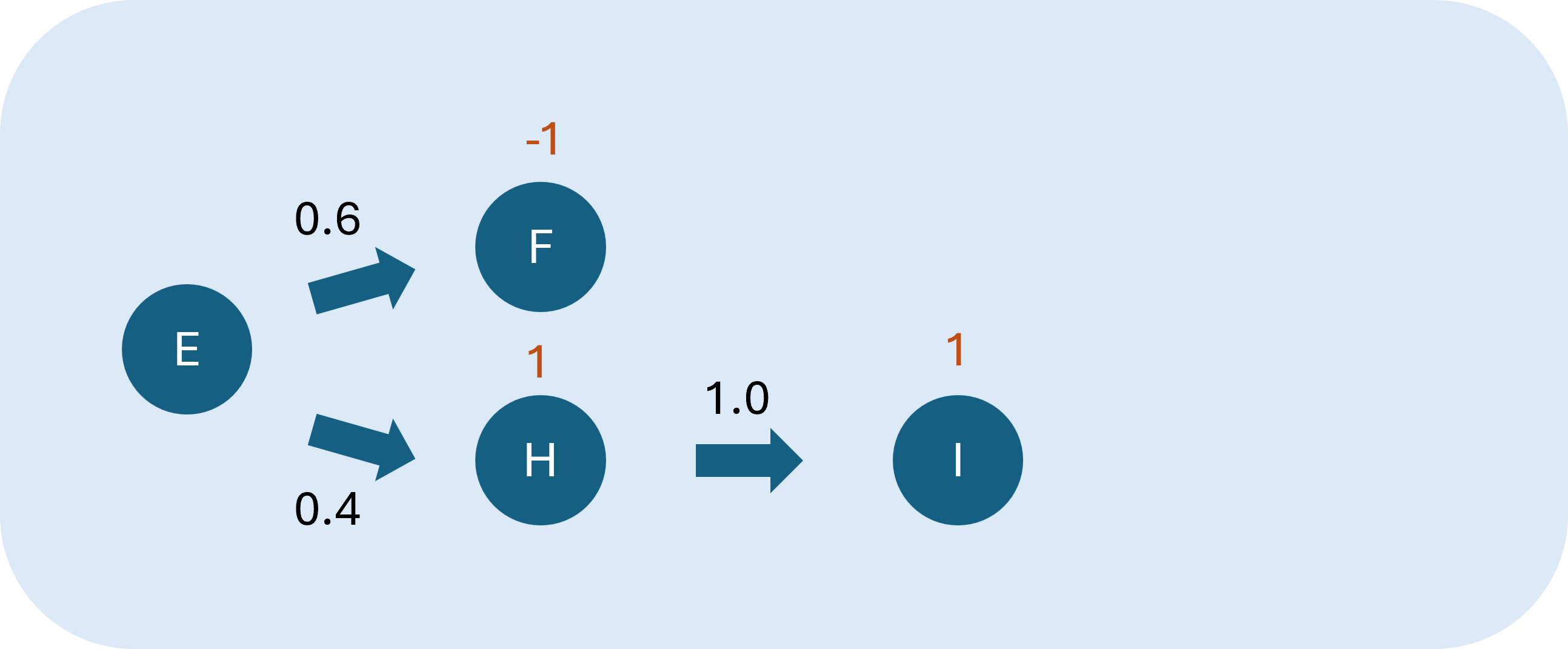
則策略2的價值為(-1)×(0.6)+2×0.4=0.2。兩者相比,策略1價值較高,因此最佳價值函數為策略1。
Q函數
又稱為狀態-行動價值函數(state-action value function),表示在策略下,於狀態採取行動得到的期望回饋。和狀態價值函數一樣,也有決定性和機率性兩種。
確定性策略
價值函數即為回饋函數,只是加上行動參數。
機率性策略
價值函數是回饋函數的期望值。
舉例
確定性策略
於策略所產生的回合,狀態A轉移至E、D、F,得到獎勵1、1、-1
- A採取行動轉移至E的Q函數
- E採取行動至D的Q函數
- D採取行動至F的Q函數
- 沒有行動,就沒有價值(例如狀態F)
機率性策略
策略的回合產生的流程如下:
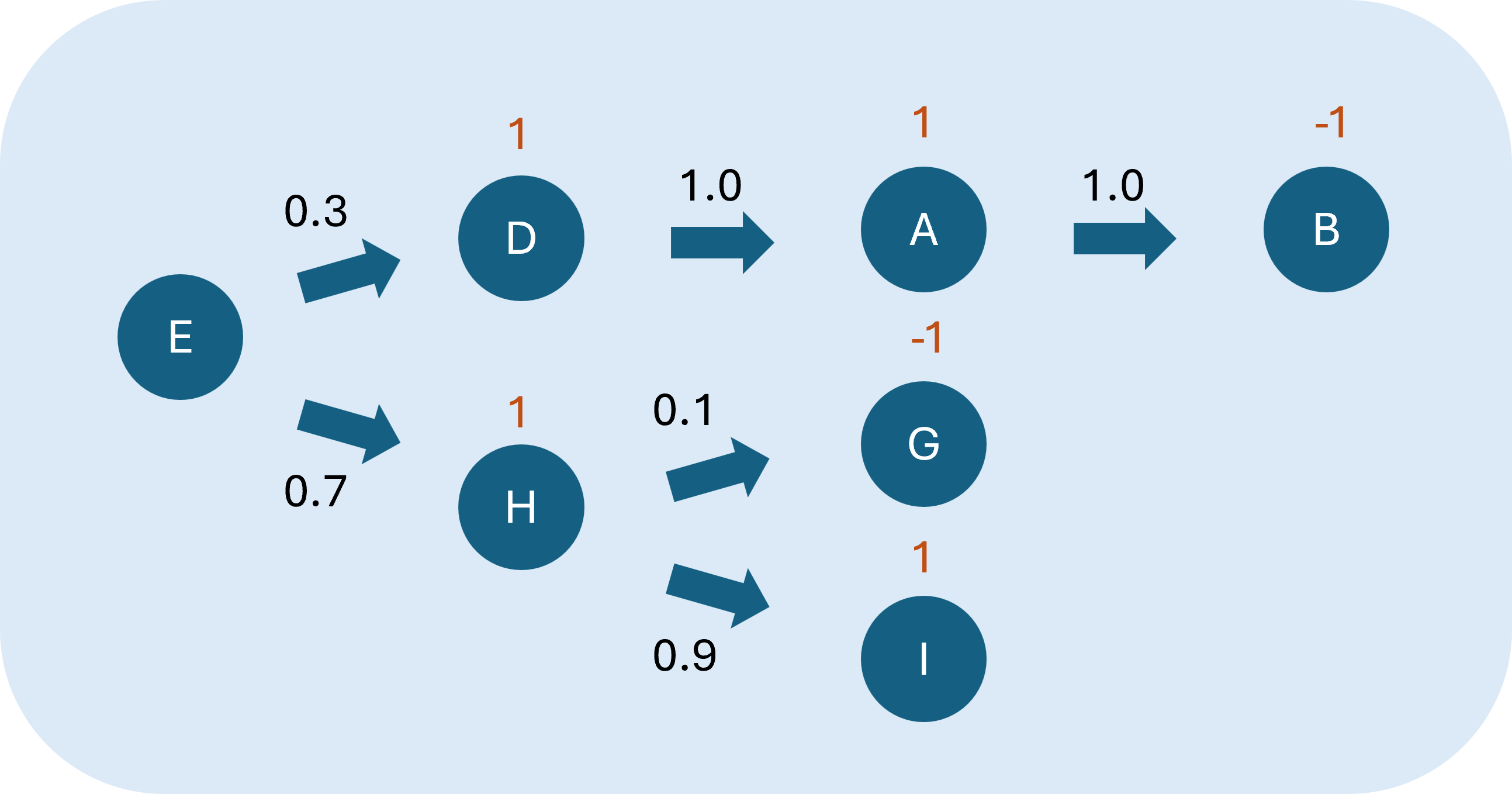
- E採取行動轉移至H的Q函數。由於已經選定行動是到H,所以這部分的獎勵為1,表示100%轉移
- E採取行動轉移至D的Q函數
最佳Q函數(optimal Q function,)
。一樣用圖3.當作策略1(),而策略2()如下圖:
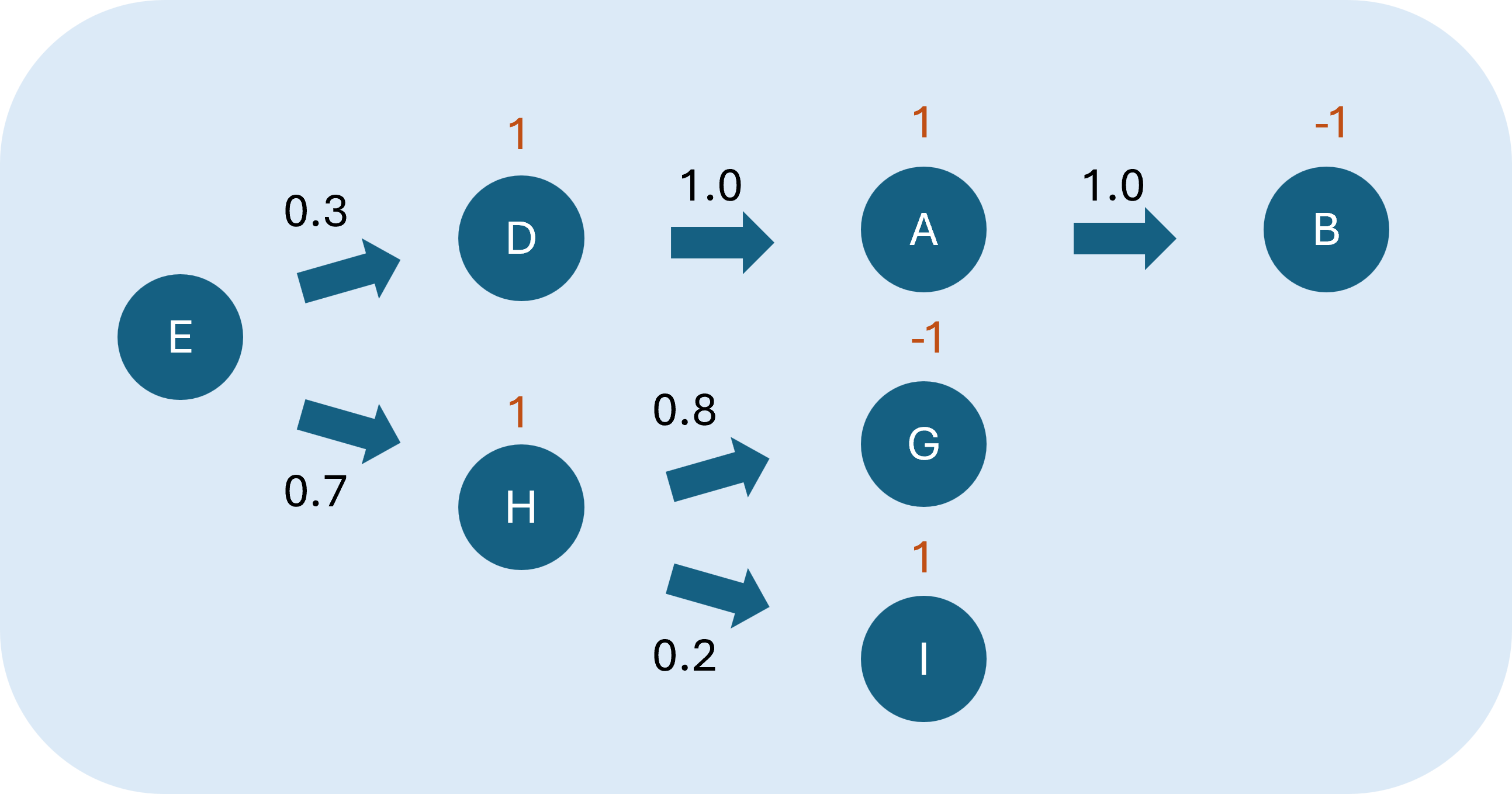
E採取行動轉移至H的Q函數,因此在這個行動)的最佳Q函數為
貝爾曼方程式(Bellman equation)
利用計算最佳價值函數/Q函數的方式,找到最佳策略。
貝爾曼價值函數
依照環境是否為機率性,以及策略是否為機率性,共2×2=4種。
確定性環境/策略
為在狀態s採取行動a轉移至狀態s’所得到的獎勵,這裡稱即時獎勵(immediate reward),表示成R函數,也可以寫成。是折扣因子,而為下個狀態s’的價值。
s狀態的價值為採取a行動轉移至s’所獲得的獎勵,加上s’狀態的價值。隨著s狀態持續往流程後端前進,其價值持續被更新,這個被稱為貝爾曼備份(Bellman backup)。當前狀態的價值只根據下一個狀態的價值來計算,稱為bootstrapping。
確定性環境/機率性策略
機率性策略使行動有不確定性,所以貝爾曼備份變成計算期望值。行動的差異,會導致轉移到的狀態也不同。指的是在狀態s採取行動a的機率。
例如下圖:
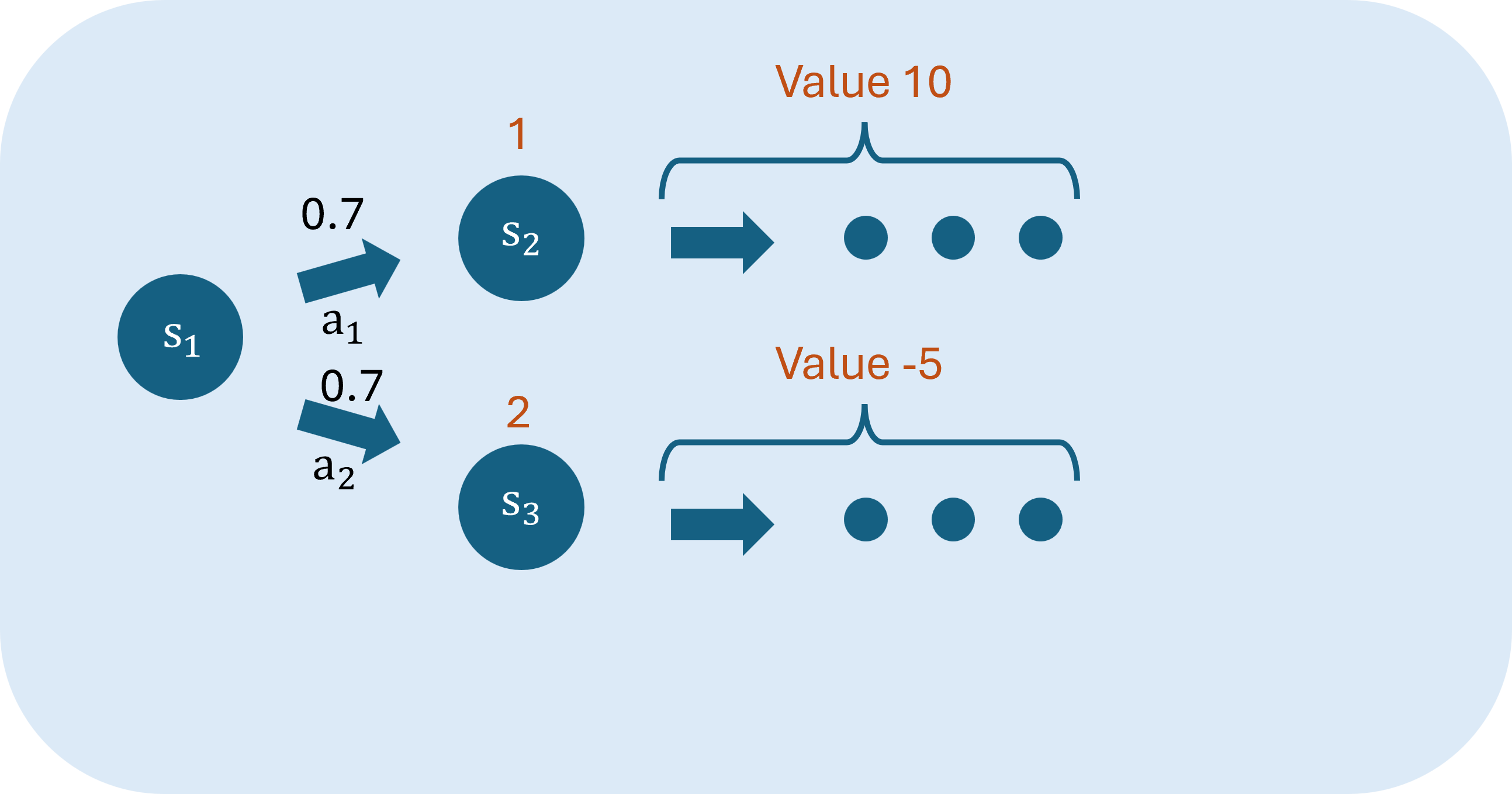
在狀態,有0.7機率採取行動,轉移至狀態,並獲得獎勵1,的價值為10;0.3機率採取行動轉移至狀態,獲得獎勵2,而的價值為-5。折扣因子為1。
則計算價值為
機率性環境/確定性策略
對環境做期望值計算。這個情境的意思是「在某個狀態固定做某個行動,但狀態的變化未必符合行動的目的」。為在狀態s採取行動a轉移至s’的機率,也可寫成。
例如下圖:

狀態,採取行動a之後,有0.4機率轉移至狀態,獲得獎勵2,的價值是10;有0.6機率轉移至狀態,獲得獎勵4,的價值是5。折扣因子為1。
計算價值為
機率性環境/策略
對環境和策略都要計算期望值。策略本身有不確定性,而環境應對行動產生的狀態轉移也有不確定性。計算步驟如下:
- 計算轉移至各狀態的價值,並乘以折扣因子
- 加上轉移至各狀態的即時獎勵
- 乘以轉移到各狀態的機率(環境不確定性),按各行動分別相加
- 各自乘以各行動的機率(策略不確定性),再相加
來看一個實際的例子,如下圖:

狀態s,有0.7機率採取行動,對應環境0.4機率轉移至狀態,獎勵1,價值10;0.6機率轉移至狀態,獎勵3,價值7。0.3機率採取行動,對應環境0.4機率轉移至狀態,獎勵2,價值-5;0.6機率轉移至狀態,獎勵-4,價值-2。折扣因子為1。
計算價值為
最佳貝爾曼價值函數
尋找最佳策略,產生最高價值。按行動分別計算,取最高者。所以,如圖7的例子,貝爾曼價值是10.4,而則為-4.8。計算貝爾曼價值時,行動本身的機率不用計算進去。比較之後,最佳貝爾曼價值為10.4。
貝爾曼Q函數
一樣有四種情況。Q函數表示狀態-行動都納入考慮。
確定性環境/策略
需要考慮到下個狀態的下個行動。貝爾曼備份為,也是更新當前狀態的Q值。例如狀態s採取行動轉移狀態至,得到獎勵8,採取行動的Q值為-2,s的Q值為8+(-2) = 6。
確定性環境/機率性策略
機率性策略造成行動的不確定性,體現在下個行動上。即使當前狀態在行動上也可能有不確定性,但因為Q值關注特定行動而被限定。折扣因子必須在下個狀態的Q值取期望值之後,再相乘。
舉個例子:
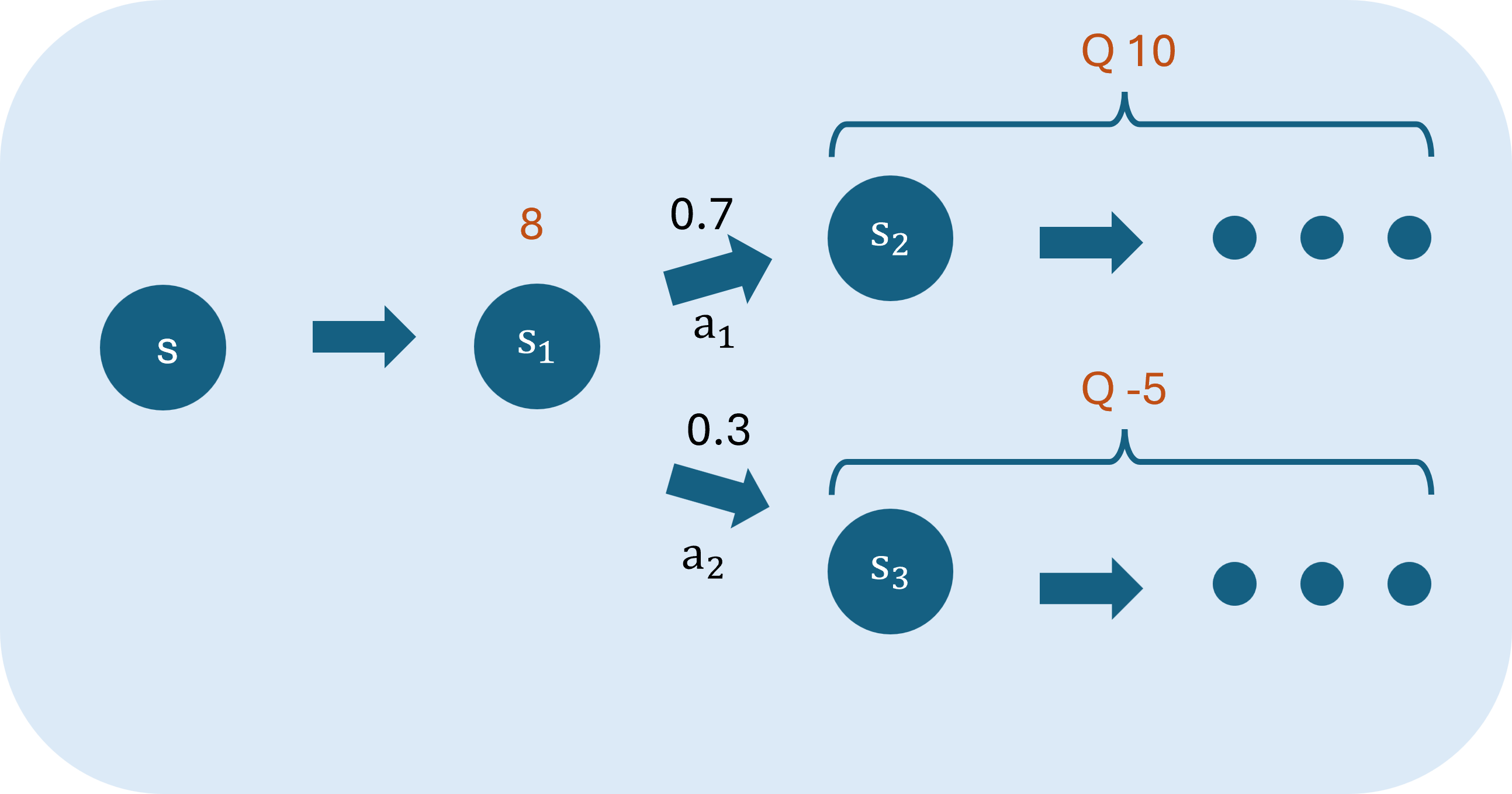
狀態s採取行動a會轉移到狀態s1s1,獎勵為8,接著有0.7機率採取行動a1a1,其Q值為10;0.3機率採取行動a2a2,Q值為-5。計算狀態s,行動a的Q值為
機率性環境/確定性策略
環境有不確定性,而策略沒有,是綁狀態(這裡指的是下個狀態),因此Q值計算好之後,要先乘上,再作後續計算。
例如下圖:
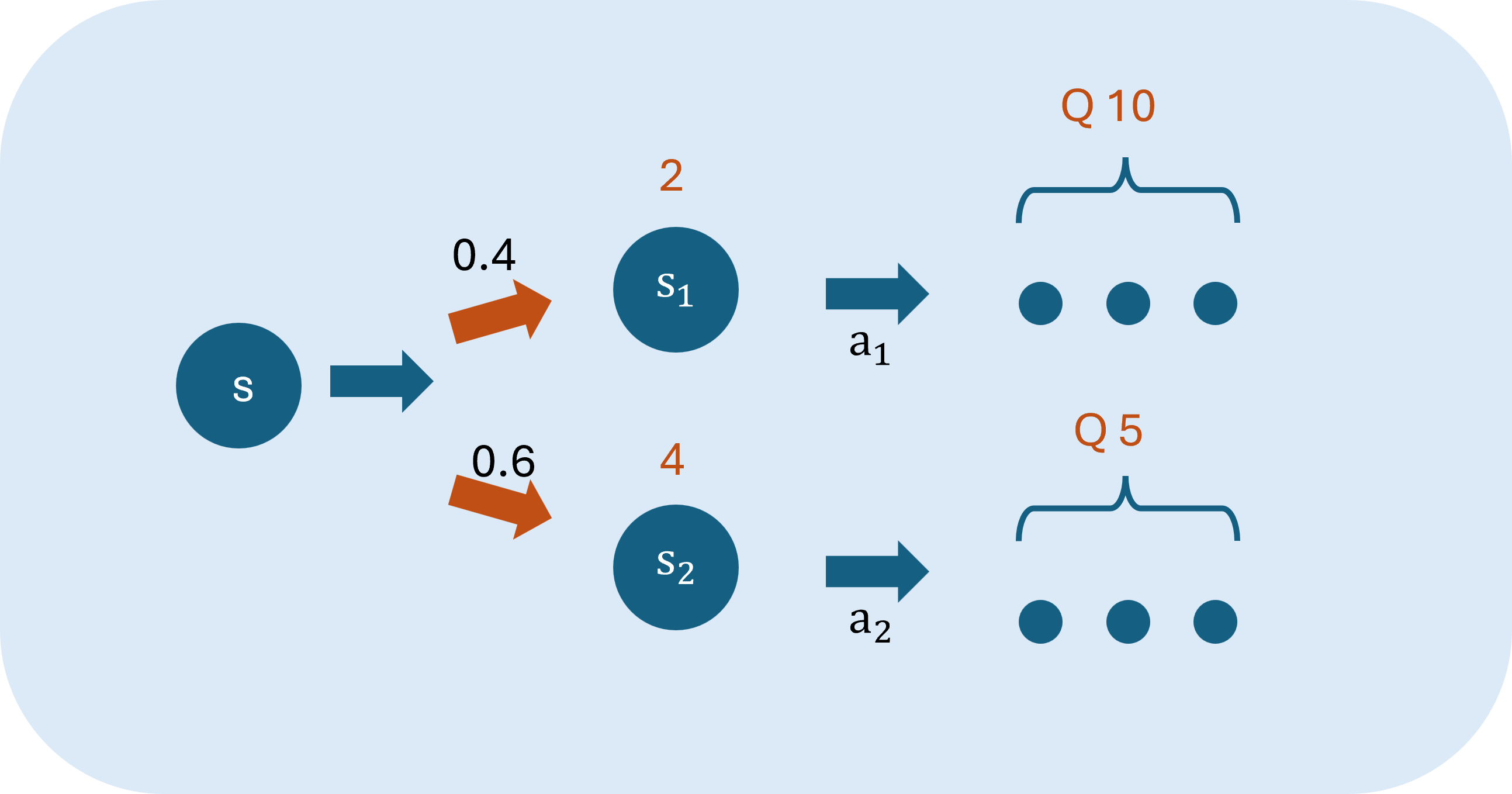
狀態s採取行動a,有0.4機率會轉移到狀態,獎勵為2,Q值為10,接著會採取行動;0.6機率轉移到狀態,獎勵為4,Q值為5,接著採取行動。計算Q值
機率性環境/策略
就是綁狀態,所以只要環境是機率性,那就是要考慮狀態不確定性,也就是會有多種狀態,各狀態的Q值計算好就要先乘,再作後續計算。
例如下圖:
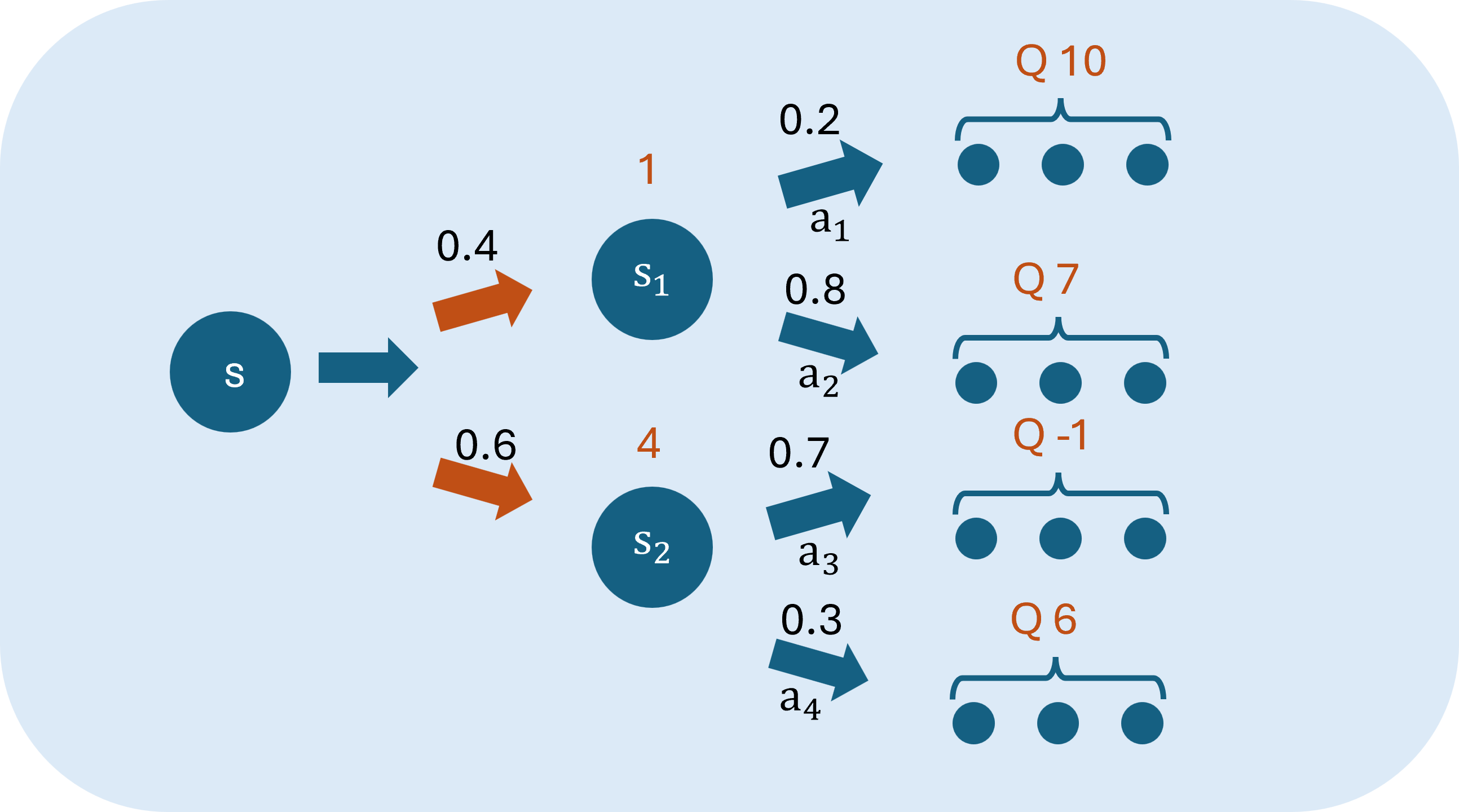
狀態s採取行動a,有0.4機率轉移狀態至,獲得獎勵1,並接著有0.2機率採取行動,Q值為10,0.8機率採取行動,Q值為7;有0.6機率採取行動至,獲得獎勵3,並接著有0.7機率採取行動,Q值為-1,0.3機率採取行動,Q值為6。計算Q值
最佳貝爾曼Q函數
看下個狀態之後的最佳策略。在不同行動間挑選最大的Q值,不必乘上挑選該行動的機率。
在圖10.的例子,狀態的最大Q值產生在,10。則在,6。所以最佳貝爾曼Q函數為
最佳價值函數/Q函數/貝爾曼之間的關係
最佳價值:挑選各行動中Q值最高者。
最佳貝爾曼價值函數:把狀態的立即獎勵拆出來,形成貝爾曼備份,用於隨狀態迭代更新。
最佳貝爾曼Q函數:和最佳貝爾曼價值函數最大的差異在於取最大值的位置。最佳貝爾曼價值函數在下個行動,以及計算最後取最大值(因為要比較當前狀態要採取的各個行動),而最佳貝爾曼Q函數只在下個行動取最大值(當前行動已經被限定了)。