強化學習簡介(5)--時序差分(temporal difference learning)
整理一下目前學到的兩個策略迭代的方法:
- 動態規劃(dynamic programming):
- 屬於基於模型(model-based)的學習方式,需要掌握環境。
- 利用下一個狀態的價值/Q值推導當前的價值/Q值。
- 可以用在連續型任務,不一定要終止(可以沒有回合限制)
- 蒙地卡羅(Monte Carlo):
- 屬於無模型(model-free)的學習方式,不需要掌握環境。
- 利用採樣的方式,以量逼近期望值,以計算價值/Q值。
- 需要回合制,要有終止狀態才能計算回饋。
看到這裡,這兩個方法,各自極限的集合就很明顯了:在無模型學習中,如果要解決連續任務(無回合)要怎麼辦?
這就是這篇的主題:時序差分法。
時序差分
時序差分(temporal difference learning,TD),和蒙地卡羅一樣可以做預測和控制。在控制功能,它還分成On-policy和Off-policy,稍後詳述。我們先來看看時序差分的價值函數如何表示。
TD價值函數
動態規劃的價值函數為
蒙地卡羅-漸進式平均的價值函數為
TD把當前的回饋,視為下個狀態的價值和當前獎勵之和(也就是上兩式黃色的地方等價),因此整合兩式為
這樣可以把回饋取代掉,就不需要被回合(終止態)限制,同時還可以用蒙地卡羅法處理未知環境的問題。為前次時間點(接觸狀態)的價值函數,即預測價值(predicted value)。則是本次接觸狀態s,採取行動a進到下個狀態s’得到的獎勵,加上下個狀態s’的價值,合稱為目標價值(target value)。
現在行動得到的目標價值,減去過去累積的預測價值,也就是就是時序差分(TD error),利用此誤差更新舊的價值,得到新的價值,並用來控制更新速率(學習速率)。
預測
假設有三個狀態,兩種行動,其狀態關係如下。
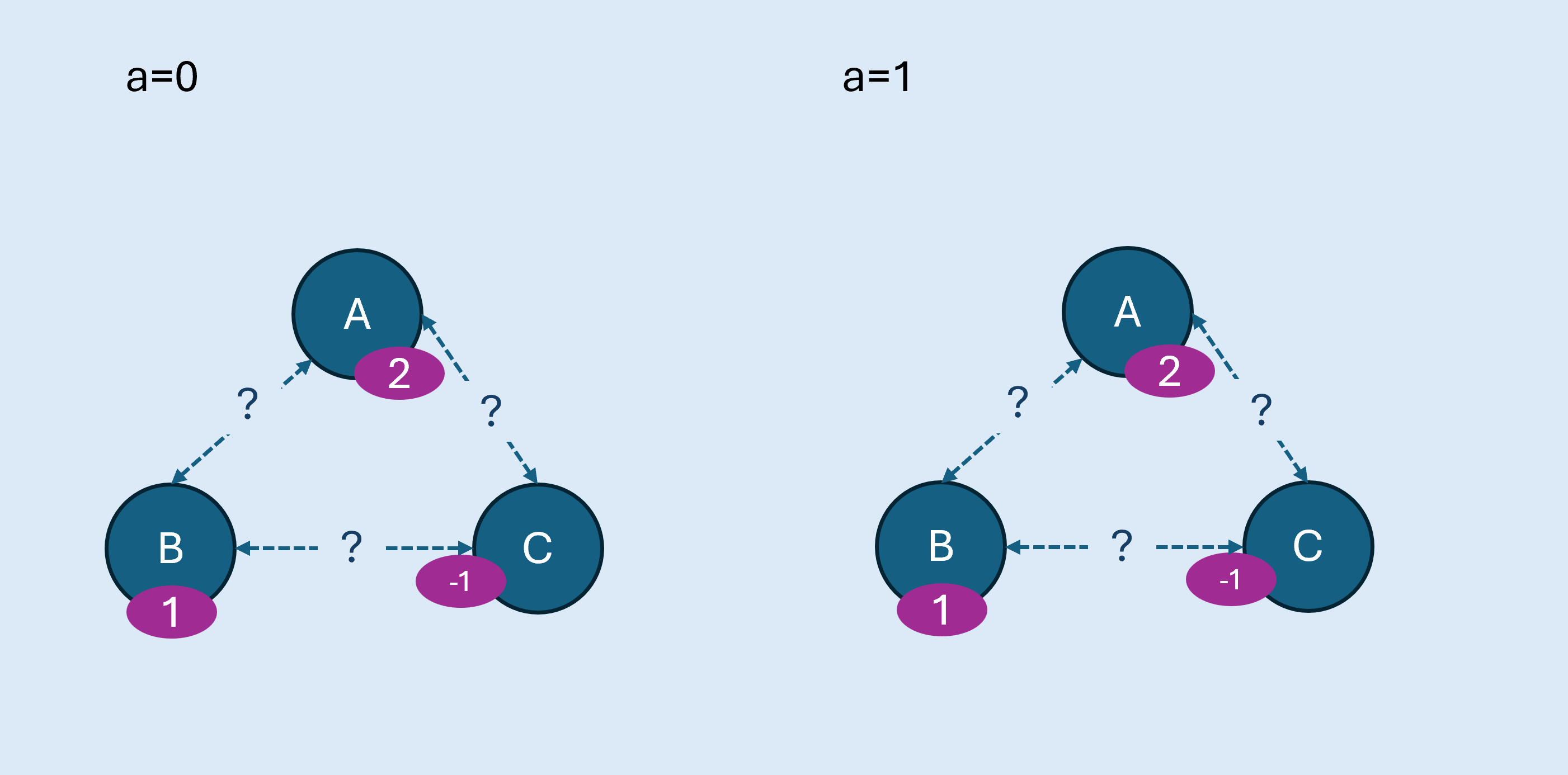
- 圖中的?表示不知道狀態轉移的機率,即未知環境。操作時,要先隨機初始價值
- 接觸時間,於狀態B隨機策略採取行動,之後狀態轉移到A,獎勵為2,依照公式代入值計算出更新的B的價值為
,此時價值表的接觸時間點更新為,且更新價值表為
- 接觸時間,於狀態A隨機策略採取行動,之後轉移到狀態C,獎勵為-1,依照公式更新,此時價值表的接觸時間點更新為,且更新價值表為
- 同上,以狀態C作為接觸時間點的當前狀態,於隨機策略採取行動,之後轉移到狀態C,獎勵為-1,依照公式更新,此時價值表的接觸時間點更新為,且更新價值表
- 狀態C作為接觸時間點的當前狀態,於隨機策略採取行動,之後轉移到狀態A,獎勵為2,依照公式更新,此時價值表的接觸時間點更新為,且更新價值表
以此程序,反覆可以持續計算各狀態的價值。
控制
On-policy
和TD預測公式的差異在於更新的是Q函數,,其中為預測Q值,而為目標Q值,兩者之差也稱為時序分差。
On policy的意思是「堅守策略」,每個行動都按照同一種策略進行。又稱為SARSA,依序為當前狀態s,採取行動a,得到獎勵r,進到下個狀態s',採取行動a'。Q值的式子為
其中a和a'屬同一策略形式,例如貪婪策略
我們看一個實際的例子。例如剛剛在預測使用的馬可夫決策過程():
- 首先建立初始化Q表。
粉色表示該狀態的最大Q值,目前剛好在A、B、C狀態都是a=1。
- 第一接觸時間點,於狀態B,抽機率,因此隨機採取行動,取a=1,狀態轉移到C獲得獎勵-1。接著再抽機率,因此選Q最大的行動為a=1,更新Q值
更新之後,狀態B變成a=0的Q值較高,因此用橘色表示更新值,而粉色值轉移到a=0。
- 第二接觸時間點,於狀態C,行動a=1是剛剛已經決定的,這裡不必再重新決定。狀態轉移到A,獲得獎勵2。接著再抽機率,隨機採取行動a=0。更新Q值
更新之後,狀態C仍然是a=1的Q值較高。
- 第三接觸時間點,於狀態A,行動a=0是剛剛已經決定的,這裡不必再重新決定。狀態轉移到C,獲得獎勵-1。接著再抽機率,因此選Q最大的行動為a=1。更新Q值
- 最佳策略為各狀態行動Q值最高的組合,若過程到此為止,則最佳策略為
Off-policy
又稱為Q learning,和SARSA最大的差別,在於每個動作依據的策略種類可以不同。它也是有當前狀態s,採取行動a,得到獎勵r,進到下個狀態s',採取行動a'。寫成式子為
但a和a'可以不是同樣的策略形式,例如a使用貪婪策略,但a'使用貪婪策略。因為a'行動固定採取Q值最高的行動,因此也可把上式寫為
我們用實際的例子來看吧。還是圖1.的馬可夫決策過程,。
- 一樣先初始化Q值,建立Q表,粉紅色亦為狀態最大Q值的行動。
- 第一時間點,狀態B,依貪婪策略抽機率,故隨機選取行動a=1,轉移到狀態C,獲得獎勵-1。接著採取貪婪策略,選取Q值最大行動a’=1。更新Q值
- 第二時間點,狀態C,需重新設計行動,因為上一時間點的a',這個時間點是a,所以要採取貪婪策略。抽取機率u,故隨機選取行動a=0,轉移到狀態A,獲得獎勵2。接著採取貪婪策略,選取Q值最大行動a’=1。更新Q值
狀態C的最大Q值變成a=0。
- 第三時間點,狀態A,需重新設計行動。抽取機率,故選取Q值最大行動a=1,轉移到狀態C,獲得獎勵-1。接著採取貪婪策略,選取Q值最大行動a’=0。更新Q值
經過這一連串步驟,當前最佳策略為。
On-policy和Off-policy最大的差別
On-policy因為當前行動和接下來的行動,都是在本次行動就根據策略決定,因此假使是用貪婪策略而非貪婪策略,則除了agent沒有探索的機會之外,也有可能在Q值更新之後,沒辦法採用當下Q值最高的行動(因為在上一接觸時間點已經決定了)。
反之,Off-policy下,如果搭配貪婪策略,每次接觸時間點開始行動時,都要再重新選擇一次,就比較能保證確實依照Q值最高的行動來執行。