檢索增強生成(Retrieval-Augmented Generation)整理(1)
理論脈絡
檢索增強生成(Retrieval-Augmented Generation,RAG)時至今日,在大語言模型橫流,各種應用概念推陳出新的當下,早已非新鮮名詞。但我一向不愛衝浪 — 我的意思是,我不需要非站在浪尖不可 — 而喜歡等前導車開出去一段時間,再決定要不要跟上。就像你們看到這篇文章的當下,一字一句仍然是我細心斟酌,用鍵盤慢慢敲出來的,而不是丟給GPT生成,我再潤稿。這不代表落後:事實上,在這沒更新任何文章的大半年,我依序訂閱過GPT、Gemini、Claude,而且也跟他們協作過專案了。再過幾個月,或許我會分享自己協作專案(個人也不喜歡使用vibe coding這個詞彙)的心得,做為新的一篇文章。
所以即便RAG已如此風行,相關介紹的文章,甚至是中文文章也不少,我還是決定來整理屬於自己版本的學習筆記和心得,同時也跟各位分享。主要整理文章來自[1],但我們先從[2]開始談起。
Naive RAG:最早的檢索增強生成概念
動機:模型內建知識庫不足以應付持續更新的外在知識
預訓練(pretrained)的做法,本來就是各種演算法或深度學習模型的基礎所在。利用已有的資料訓練模型的參數,再於類似的資料中運行(inference)。自然語言模型也不例外,利用這樣的做法可以解決很多常態、重複性高的問題。大語言模型使用更龐大的語料庫訓練,所以能解決的問題層面,比起傳統的自然語言模型更廣。
但自然語言模型,比起電腦視覺模型更容易遇到的狀況是,詢問的問題超過原本訓練的資料範圍。如果把模型當做類似搜尋引擎的功能來使用,由於現在資訊成長的速度太快,預訓練的模型壽命週期將被壓縮得很短。如果因此反覆更新預訓練模型,則要耗費大量時間和金錢。另一方面,因為自然語言模型生成文字屬於機率性質,即使文法正確,其回答真實性,無論是否屬於已訓練之資料範疇,都可能出錯(即幻覺,hallucination)。
為了提升模型更新的效率,也提升模型回答的正確性,部分研究將模型結合「參數化記憶」(或模型內記憶,parametric memories,即訓練模型內部之參數)和「非參數化記憶」(或模型外記憶,non-parametric memories,即檢索式記憶),以擴大知識庫,並更明確的指向知識來源(避免幻覺)。具體的做法是使用一個可微分的檢索器(differentialble retreiver),接在原本的模型上面。在那個年代(其實不過6-7年前,算了,深度學習的濫觴AlexNet也不過12年前而已),自然語言的核心訓練任務是masked language model,即遮住上下文,要模型預測遮住的文字是什麼。這類訓練任務出產的最赫赫有名的模型,就是BERT,正是GPT橫空出世前,主宰自然語言領域很長一段時間的霸主。
RAG的概念,基於結合兩種記憶形式的模式,把可微分的檢索器接在生成式模型上(2021年GPT還沒這麼紅,GPT-3是2020年7月推出,可是真正轟炸世界,開啟大語言模型時代的GPT-4是到2022年底才推出)。當時接的生成式模型是Seq2Seq,其實也不是很新的模型了(transformer 2017年就推出,而Seq2Seq概念上更早於這之前)。模型外記憶是利用可微分的檢索器建立的索引向量([2]文章中是把維基百科當作知識庫)。
RAG的流程
間單說,由檢索器依據輸入(input)搜尋知識庫找到資料,並把資料和輸入一起送進模型。模型依據資料和輸入再輸出。[2]中有再針對檢索器如何找資料說明,我想這也是RAG的核心之一:
1. 輸入x,被檢索器編碼為向量q(x)
2. 知識庫文件,被檢索器編碼為向量d(z)
3. 兩向量內積,檢索器依據內積結果評分,取最高的K個做為候選。
編碼的過程採稠密向量(dense vector,向量中大部分為非0值),因此檢索器又被稱為dense passage retriever(DPR)。取最高的K個可以是基於整個輸出,或是基於每個token(這邊可以代指每個字),取決於假設搜索出來的文件是對整個輸出都有貢獻,還是針對個別的字。
檢索器和模型是一起被訓練的。檢索器訓練編碼方式,而模型當然就是和往常一樣的訓練方式,讓他具備語料庫內文字的關聯能力。在[2],因為已經提前鎖定外部知識庫是維基百科,所以訓練時除了建立檢索器編碼的能力,也一併把維基百科的索引編碼好了。使用時,直接就可以調用維基百科的知識。
接下來這段會把上面的段落用數學式表示,更清楚。如果沒興趣,或看不懂的話可以直接跳過,不影響閱讀。

數學方法
A. 框架
如圖1所示,整個模型框架分兩部分:
- 檢索器p(z|x),具有參數η,將輸入x編碼為q(x),將知識庫分段(passage)之後編碼為d(z),根據內積或cosine相似度,基於整個output或token,選出前K個分段。
- 生成式模型,具有參數θ(參數化記憶),依據輸入x,檢索器輸入分段z,以及前面的輸出token(共i-1個),輸出第i個token。
這邊有一個問題,技術上論文有處理(或規避掉),但跟模型可解釋性有關:怎麼知道輸出的結果和哪一段知識庫有關係?
在[2],應對方式是邊際化(marginilization)。沒有人工去標註這些知識庫段落,其實是沒辦法精確得知出處的。作者想到的辦法是把它視為一個隱變量(latent variable,即無法觀測的變數),利用加權求和的方式輸出,這樣就能讓檢索器在訓練過程中,自己去學到權重。這個權重其實是一個正規化(normalization)機率分布,也就是p(z|x)。然後訓練過程採用最大似然(maximum likelihood),同時更新模型和檢索器的參數。這樣就能實行端到端的訓練。關於模型本身的內容,下面會談到。
實驗時提出了兩種模型,使用不同的邊際化方法。第一種叫RAG-sequence,模型使用單一文件(document)預測不同的token。第二種叫RAG-token,模型使用不同文件預測不同的token。以下我們來看這兩種模型的內容。
B. 模型
RAG-sequence模型
如上所說,這種模型是使用單一文件預測整個輸出,包含每個token。實務上,檢索器挑選K個知識庫段落,並用邊際化處理之後,直接完成全部輸出。
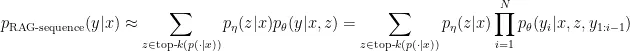
第二個等號右邊的式子,只是條件機率迭代的連續乘積。
RAG-token模型
這種模型則是把在每輸出一個token的時候,都針對K個知識庫段落做一次邊際化。在不同的token,有可能得到不同的權重(機率),因此知識庫的組合稍有不同,也就是上面說的「不同文件」。
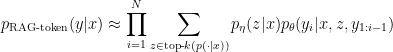
因為每個token都重新做邊緣化,所以條件機率的迭代放到sum符號的外面。
若是做序列分類(例如是非題、推測文中情緒正負面…一些很「古典」的NLP任務),因為sequence可視為1個token,此時兩模型效果等價。
C. 檢索器(DPR)
前面提到,檢索器是兩個編碼器,一個對應輸入,另一個對應知識庫。[2]提到,編碼器即是BERT。其實也合理,那個年代BERT就是為了這類編碼任務訓練的。[2]提到訓練時,會建立檢索器的初始化參數並建立文件編碼。文件邊碼即為非參數化記憶。
D. 訓練
如上面所提到,檢索器和模型是一起訓練的。文件並沒有標註,因此無法直接監督模型是從哪個文件取得答案。整個訓練使用最大似然,即最小負對數
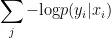
以隨機梯度下降的方式反向傳播訓練。
E. 解碼
在測試階段,為了篩選出最終的輸出,必須進行解碼。這裡解碼的意思,不是Seq2Seq那種把embeddings投射回人類看得懂的文字句子的那種decoding,而是從候選的文字/句子的集合中,選出最有可能的作為輸出。兩種模型的做法不太一樣。
RAG-token:因為一開始就是針對每個輸出的文字都做一次邊際化,所以其實已經在模型運算的過程中就完成了,只看輸出過程本身很像Seq2Seq。只是,輸出前有經過RAG的文件機率加權的調整。因此,在這個過程中,可以知道每個token最可能的來源是哪個文件(權重最高者)。這就稍微為模型可解釋性做出貢獻。
RAG-sequence:在模型運算過程中,是先做邊際化,得到一個z,然後全部的輸出都靠這個z的,因此沒辦法像RAG-token這樣逐token解碼。替代方案是對每個文件z_i,都做一次運算,得到數個句子。把所有的z都跑完之後,會得到一大群句子,及這些句子各自在對應的文件時的機率。這時彙總,將各文件的機率(權重)乘以這些句子的機率,就可以知道最後哪個句子的分數最高,以它作為最終輸出。這裡面有兩種情況:
- 一個句子只出現在一個文件:這種最單純。
- 一個句子出現在多個文件:這時要加權加總。
所以並不是只看某個句子機率最高,就斷定他一定是最後的勝者,因為還要看他所在的文件的權重,以及其他句子有沒有重複在其他文件也出現,機率又是如何。在某些情況中,那些重複出現的句子,如果在各文件能保持一定的機率,加權加總之後是有機會逆轉的。
實務上,[2]有提到,y還是會在解碼前先被輸出來,這也符合前面提到的模型運算方式(式1.)。因此,解碼的過程比較像單純在看這個輸出最可能的來源是哪個文件,所以一樣是提高模型的可解釋性。比較有效率的做法是,把針對z_i能產生的y集合找到之後,其他的y在這個(x,z_i)組合的機率都逼近0,以降低後續條件機率的計算量。
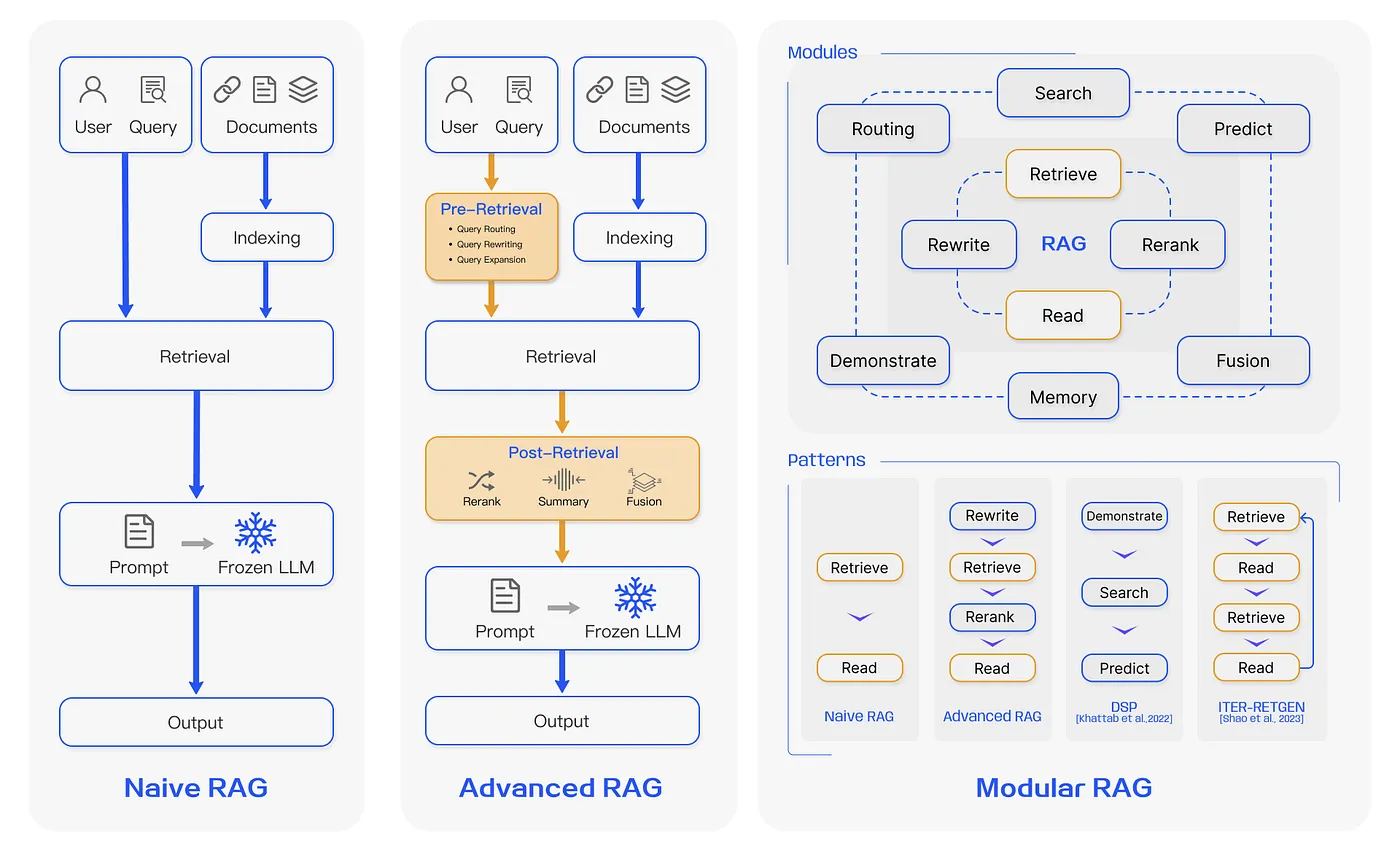
Naive RAG的困境
檢索準確度:檢索器是否正確找到能回答問題的資料,很大影響最終RAG模型的回答是否正確。但常常檢索器是找到沒有對齊或不相關的資料,所以導致最後輸出也偏差很多。
生成文字的穩定性:RAG的模型仍然無法完全避免幻覺,即生成之文字可能並非從檢索的文件而來。且文字生成的品質本身也不穩定。
檢索的資訊反而干擾生成品質:例如生成模型過度依賴檢索到的資訊,全部照本宣科,而沒有融合進整段輸出,配合段落主旨;檢索到多個資訊指向同一件事,導致生成時反覆敘述;拼接不同來源資訊時,無法維持語意的連貫,充滿斧鑿痕跡等等。對人類來說未必看不懂,有部分純粹是品質上的要求。
因此,RAG又經過了後續的改良。
接下來讓我們把焦點轉向[1]。
Advance RAG:針對檢索改良
Advance RAG是為了解決naive RAG而被提出的。他使用一些方法來處理搜尋的問題:例如,在索引上,使用了sliding window,finegrain segmentation等方式,讓索引本身變得更有關聯性,也提升精確度。不過,advance RAG主要是在檢索上面下功夫,依據流程順序,分為檢索前(pre-retrieval)和檢索後(post-retrieval)兩大類。
檢索來源(retrieval source)
A. 資料結構
RAG一開始的時候,檢索的資料大部分是文本。這類資料基本上是完全沒有結構的 — 除非你把段落或標題當作結構,但在背後的資料結構邏輯上,他還是沒有能提醒機器「這邊是段落開始」「這邊是標題」等等有效的訊號或符號。後來,檢索範圍擴大到PDF或HTML這類半結構化資料,他們有明確的符號或訊號,告訴機器標題或段落的起始和終點,但內文仍然是連續性的。
知識圖譜(Knowledge graph, KG)的出現,讓結構化資料也進入RAG的範疇。知識之間的關聯性使用相連的邊建立,而每個獨立的知識本身是一個節點。因此,RAG可以更輕易的建立索引,而且更精確。這類資料最困難的地方反而是在建立圖。
更進一步了解圖像(graph):圖像化神經網路(1):Graph Neural Network小簡介
現在由於LLM盛行,也有利用LLM本身來建立資料文本的方法。背後原理主要是認為這類資料在檢索時,比較具有「機器」的風格,也就比較容易被機器理解、接受,進而更有效率的建立索引,並維持正確性。這類方法主要是在提升模型本身的效率。
B. 資料細緻度
資料細緻度是一個天平的兩端:資料關聯性和資料精確性。如果把資料來源拆分成單位內容大的文件,那單一文件裡面可以看到比較多相關連資料的機率會增加,但同時,資料裡面不適合回答問題的部分也會增多。反之,內容少的話有機會只拿到完全符合問題的資料,但如果查偏了,就會什麼都沒有。
在文本,依照資料細緻度排序,由細到粗為字元(token)、片語(phrase)、文句(sentence)、段落(proposition)、區塊(chunk)、文件(document)。DenseX提出使用段落當作檢索單元,因為他是自然語言架構中,能有完整語意的最小單元。段落目前也是主要被做為檢索單元的對象。在圖像,能被當作檢索單元的有值、三件套(triplet,指兩個截點和與其關聯的邊緣,或指關聯當中的主體、受體,和關聯的邊緣,兩種指涉是同樣意思),以及次圖像(subgraph)。
檢索前(pre-retrieval)
主要是最佳化索引,以及改善提問(或輸入,query)。
A. 最佳化索引
資料切分:
最常見的方法是把文件拆分成固定字元大小的資料。但這樣做,無論容量大小,都可能剛好把一個句子拆成不同區塊。所以有一些改良的方法,例如sliding window,調整切分避免截斷句子,或者利用分層檢索的方式,不過仍難以保持語意完整性和內容長度的平衡(即上面提到的資料細緻度)。Small2Big提出改以語句當作檢索單元,然後把語句後面的長文字區塊交給LLM來處理。
賦予中介資料(metadata):
這也是一個好方法,把切分的資料附上一些相關資訊,例如資料出處、頁數、作者、分類等等。這些資訊的好處是明顯的結構化,而且不用顧慮語意連貫性,通常都是獨立的。檢索時,可以先根據中介資料過濾,減少搜索範圍。甚至,可以將時間權重賦予在中介資料上,讓檢索時可以優先搜尋新的資料,而避免資料過時。中介資料也可以是合成的,例如關於切分資料的摘要或總結、切分資料能回答的問題等等。最近也有利用LLM來根據切分資料,生成可回答的問題,並把提問和這些生成的問題做相似度比較,以降低提問和回答之間的語意隔閡。
結構化索引:
這邊提兩個方法:
- 層次性索引:先把每個拆分資料做總結,然後放在節點上供檢索。其下轄整段拆分資料。這樣可以讓做為索引的資料量降低,連帶降低幻覺的機會。
- 知識圖譜索引:層次索引如果搭配圖像管理,效果更好。圖像本質上使用邊緣來連接節點,這個方式除了強調節點間的關聯性,也過濾掉不消干的資訊,能有效降低幻覺產生。圖像的資料可以轉成相關列表(adjacent list)或者相關的格式,這種格式讓機器易於辨認,因此還可以提高檢索正確性。節點可以直接標上索引標籤,並在節點內附上中介資料,提取節點時,才顯示其背後的原文內容,降低檢索困難度。
B. 提問改良
使用者的提問常常不精確或不清楚(包括我有時候也是這樣,所以LLM剛推出的時候才一堆人在推那些提示或詠唱魔法,甚至開課)。提問有時很複雜,但使用的語言或文法不正確。另一個問題是縮寫。很多縮寫常常代表著不同意義,有些是在不同領域時意義不同,有些則是在同一個領域也代表不同意義。例如CNN在美國或媒體圈代表美國有線電視新聞網,在深度學習領域指的是卷積神經網路。因此,衍伸出一些改良原始提問,以便更正確的檢索資料的方法:
提問擴充:
把簡單的事情搞複雜 — 不是,是把過於精簡的提問擴寫 — 以便更精確的理解提問。讓提問的內文更豐富,有助於檢索。這裡提供幾個具體的做法:
- 利用提示工程來擴充:這個算是半人為的方式,但當然指向性很高,提問會往人類期望的方向變得準確。
- 拆解問題:把問題拆成數個小問題,並藉由串連回答小問題,得到問題得完整答案。拆解問題的過程中,也會需要補充提問內文。
- 驗證鏈:把擴充後的提問交給LLM驗證。一般而言,經過驗證後的提問會比較可靠。
提問轉換:
把原始提問轉成比較好理解的問題。多半是利用提示工程或直接讓LLM來改寫提問。
提問路徑設定:
利用提問本身牽涉的潛在中介資料分類,或用語意分類,引導檢索的方向。
改良嵌入向量
核心精神是盡量讓提問的向量和拆分文本的語意空間對齊,這樣才能確保他們的向量相似度可以連接到語意相似度。具體做法有兩類:
合成式檢索:
把離散(sparse)和緻密(dense)向量的檢索器合成在一起,讓他同時可以捕捉各自相關的特徵。
微調嵌入模型:
利用大語言模型的結果、或合併人類的標註進行監督式學習。也可以搭配強化學習,或者乾脆使用領域知識相關的資料來做微調。
Adapter(調適器)
主要是使用一個模組,引導模型改善提問和檢索的能力。其背後主要還是協助特徵對齊。
檢索後(post-retreival)
在幾年前,語言模型的文字生成並不如今日成熟,所以最好不要把檢索結果直接當輸出。這裡提出兩個方法:一個是針對檢索結果改良,一個是調整輸出([1]中把它認定是調整LLM配合輸出)。
A. 檢索結果改良
LLM似乎也有把注意力集中在段落的開始和結束的狀況,因此,要避免把關鍵資訊放在段落的中間。
重新排序:
將最相關的拆分文本提到最前面,有助於降低輸出雜訊。這個過程可以用ruled-base model,或用BERT系列的模型。
文本篩選/壓縮:
把所有檢索文本直接串接丟給LLM,其實反而造成太多雜訊,而降低LLM萃取關鍵資訊的能力。利用一些「小」語言模型(GPT-2、LLaMA-7B…只是相對於現在的LLM叫小,其實也不小),可以把文本不相關的字元移除,產生一個對於人類理解很難,但對LLM理解容易的文本。這樣可以省去調整LLM的心力。另一個做法是利用小語言模型進一步過濾檢索到的文本,或讓LLM先過濾文本再輸出,都可以提升輸出的品質。
B. 調整輸出(LLM)
主要是將LLM調整到更適應檢索領域相關的知識。所以屬於LLM的再訓練,但不必重新訓練,僅做參數調整。
模組化(modular)RAG:靈活調整,因應多變任務
這個階段,算是把naive和advance RAG拿來組合運用了。把RAG裡面檢索/生成的順序變成模組,修改中間的流程或添加套件,使用階段式處理或端到端聯合訓練,以符合不同情境的需求。以下分幾個種類介紹:
新增模組
搜尋模組:針對特定情境,且能直接跨工具搜尋資料,例如搜尋引擎、資料庫、知識圖譜等等。
RAG融合/平行提問:將原始提問擴寫為從不同角度提問,再將這些提問平行查詢,搭配重新排列檢索結果順序,以減少檢索方向的偏差。
記憶模組:利用LLM的長內文記憶,創造一個比較久的記憶池,以確保提問、檢索文本的語意能更對齊。
Routing:在不同的檢索路徑(總結性搜尋、特定資料庫搜尋、合併不同資訊來源搜尋)中,找到最好的
預測模組:利用LLM先預測針對提問可能的答案,當做模擬檢索文本可能的樣式,再來和檢索到的資料比對,以降低雜訊。
任務調適模組:針對不同任務協助RAG模型,例如在0樣本訓練任務中(未知樣本,zero-shot),協助RAG自動化產生檢索提示,或者在少樣本訓練中(few-shot),協助RAG產生符合特定任務的檢索。
關於few-shot和zero-shot,可以看這篇文章
新型態(流程重構)
使RAG不再局限於原有的提問-檢索-生成的流程,修改互動方式,以強化RAG的效益。
精煉提問:利用LLM來迭代、改善提問品質。這包括讓LLM回饋RAG檢索提問的品質、直接讓LLM依據原始提問生成檢索提問、或者從模型權重精煉提問品質。
提問流程重構:迭代檢索,即如果檢索的品質不夠好,可以再反覆檢索。依據檢索的品質決定是否要再進入迭代。
這邊把三種類型的RAG流程圖統整出來,出處來自[1]
在LLM時代,RAG的角色
因為LLM本身的強力,RAG的功能已經不再像當初被提出來,將檢索做為一個輔助輸出的重要部分,而是整個流程都退居輔助LLM的角色。在這個情境下,RAG會被拿來和其他輔助LLM的方法比較,例如提示工程,或者微調LLM參數等等。不過,[1]提到,這些方法其實各擅勝長,並沒有角色重疊需要競爭的問題。對於適用情境,論文中將他分為2×2=4,即依據外部知識需求量和調適模型需求量的組合。
提示工程適合外部知識需求量和薄型調適需求量皆低的情境,也就是通用型的情境,完全依賴LLM本身的知識庫和上下文能力。RAG將重點放在檢索,所以當然主要適合外部知識需求量大的場景。而微調,一般是用在更新模型,調整他的模式,所以比較著重於模型調適需求。微調比較需要完整的資料集和資源做訓練,而且也專注於資料集所在的領域,而比較不擅長其他外部知識。情境區分示意圖如下:
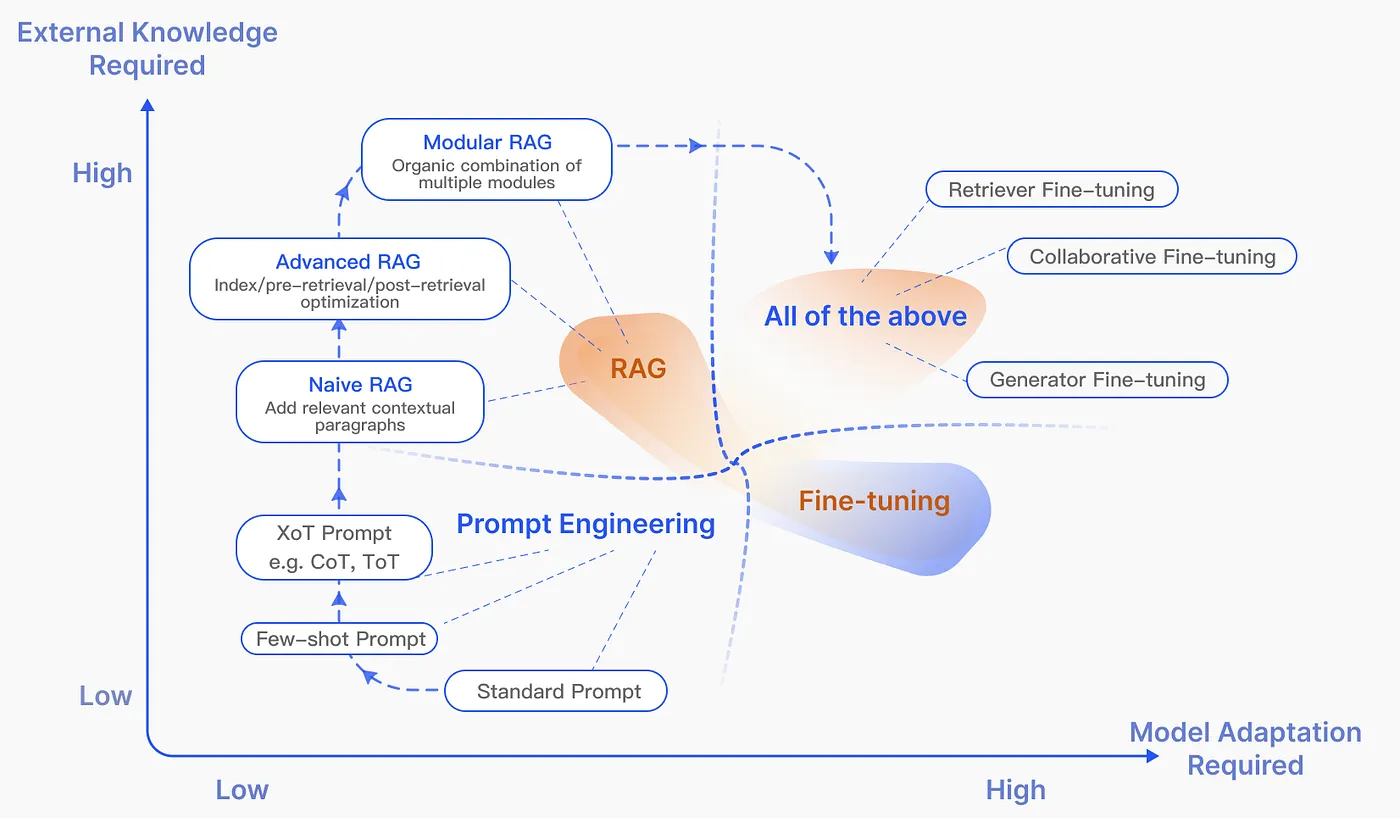
如圖所示,實際上方法彼此之間並不互斥。使用者應該依據任務的情境判斷,選擇適合的方法,或組合不同的方法。面對越高階的需求(也就是一般人認為的無所不能,或至少輕易勝任很多工作),背後往往要下很多功夫,意思就是三種方法大概都要用上了。所以,不要輕視任何方法,以免顧此失彼。
總結
在這篇文章中,我們比較了不同的RAG模式,並依據時代演進排序。因為RAG發展的歷程,剛好跨越LLM蓬勃發展的年代,因此其角色有所改變。在下一篇系列文章,我可能會想實作一個naive RAG模型,因為架構相對單純,可能比較可以看到想要的變化。就要看之後什麼時候比較有空了。我們下篇文章見~
參考資料
[1] Retrieval-Augmented Generation for Large Language Models: A Survey. Y. Gao et al.
[2] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. A. Piktus et al.