DeepSeek mHC (manifold-contrained Hyper-Connections)完整解析
Residual block概念的再進化
DeepSeek看起來是喜歡在年末年初的時間發表新作啊。繼去年的V3/R1,今年DeepSeek再次於跨年之際,提出一個改變過往深度學習架構的概念:manifold-contrained hyper-connections,直譯為流體限制超連結,無論從物理或深度學習的角度來看,都還是非常抽象的名詞。不過,要一言以蔽之,就是「使用多通道增加訊息重組的機會,並設法維持已有運算量和效率」。還是很抽象嗎?沒關係,這就是這篇文章存在的目的。
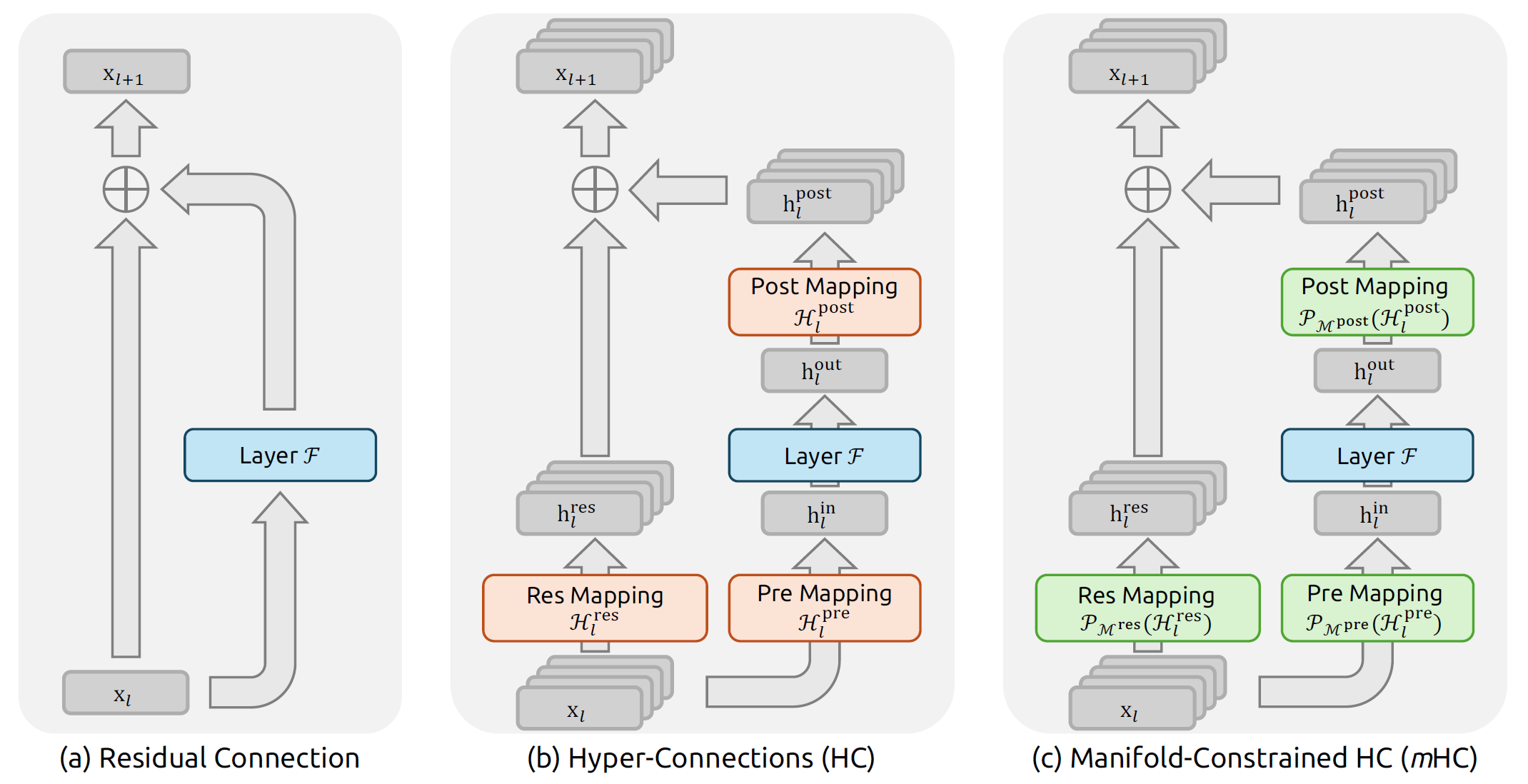
從Residual到HC
2016年提出的ResNet[2]絕對是繼2013年AlexNet之後,另一個深度學習的重大里程碑。當時的硬體算力,已經開始足夠支援反覆疊加層數的模型。要知道,最早深度學習的定義是有隱藏層,只要超過3層(一說5層)就符合了,對比現在動輒成千上百層的巨大模型,根本是難以想像的差距。
而這樣的演變也不過發生在不到15年間而已。
總之,隨著層數增加,大家發現一件事:模型並沒有真正因為這樣提升效益,相反的,還開始退步。這中間有許多原因,但其中之一是,隨著層數堆疊,特徵的萃取越來越高維,到最後失去了原本特徵的本質,像是迷失一樣。另一方面,梯度的反向傳播依靠偏微分和鏈鎖率,每一層傳播都會消耗一些。層數多了以後,傳到最前面層的梯度非常非常小,根本無力更新權重,或更新有限。
那要怎麼解決這個問題?ResNet就提出Residual Block的概念:將某一層的資訊複製一份,複製的這份直接繞過接下來數個層,到達block底端,和經過原本好幾層萃取的特徵相加,然後進入下一個block。這個繞過中間好幾層,直達block底端的路徑,又被稱作skip connection或identity mapping。這樣一來,較淺層被萃取的特徵,可以保留一部分供模型較深層萃取,而不會永遠只能萃取到前數層的,已經相對較深層的特徵。梯度傳播也同時多了一個路徑,確保到淺層時,仍有梯度可以更新權重。這個劃時代的觀念最早是用在電腦視覺模型,也就是以卷積神經網路(CNN)為主的模型。當然,2017年Transformer[3]推出的時候,也就直接把這個技巧運用在模型上。
回過頭來看Residual block。如圖1(a),一個block可以表示為如下的式子:
Identity mapping的特性,確保複製的這份,在送到block底端的時候不經過任何轉換,這點很重要。任何一點的變換,雖然在單一block裡面影響不大,但對大量堆疊的模型就非常不利。特徵可能會失真,甚至造成梯度難以收斂的嚴重後果。這在後面進入文章主題--mHC--時,會再次提到。
式(1)在經過多個block堆疊之後,可寫成
2024年,論文[4]提出了hyper-connection的概念,希望增加「訊息通道」。如圖1(b),相較於圖1(a),在identity mapping的地方多了好多條通道。此外,這些通道也並非只是單純的單一通道複製品,而是在這個mapping的過程中,彼此之間也做訊息交流,即res mapping()。
圖1(b)同時揭示原本經過的地方,必須先經過一個pre mapping(),再經過一個post mapping(),讓經過的通道數仍維持在1,而進出則維持n,以和identity mapping一致。這個設計,讓通道增加的同時,並不會增加的計算量(floating point operation,FLOP),從而不增加太多算力負擔。如此就不會落入為了增加訊息通道,勢必要同步擴張FLOP的陷阱,他們稱之為解耦(decoupling)。
注意,增加訊息通道,雖然讓輸入輸出在維度上是變成,但和把特徵維度擴展為原本n倍是不一樣的。特徵維度擴展為n倍,通常代表萃取特徵的核要增加,但在這裡,最初只是把一樣的輸入複製n倍,然後藉由每一個block裡面的res mapping做訊息交流,因此,特徵的維度實際上仍為。
單一個HC block計算如下:
而堆疊的HC block則因為res mapping的關係,出現連乘:
而這就是問題所在。原本residual block裡的identity mapping,是完全一樣的訊息,隨著block疊加,中間的訊息都還是保持原樣,所以沒有問題。但我們現在使用res mapping,他是可學的權重,每一個block裡面都會做乘法、加法,這時訊號就改變了。我們所得到的訊號,不再是一開始要傳的,「複製的」訊號。如果res mapping沒有被限制,那就會造成模型運算不穩定。而這種不穩定,隨著block堆疊越多,越被放大,最後就會破壞模型的效益。
另外一個問題是,HC雖然降低了的FLOP,但res mapping這邊對於硬體特別是記憶體的消耗仍然很大(畢竟被放大n倍)。然而HC的原始設計裡並沒有針對這個問題處理。
以上這兩個問題,就是DeepSeek提出這篇mHC想要解決的。
重新盤點問題
先定義以下變數:在第層的HC block中,
- 作為輸入,維度為
- 它會被擴展為n倍,變成一個隱藏輸入
- 在HC block有運算的這側,有,而保留訊號側則有
在HC的公式裡,3.裡的mapping實際上由兩組係數計算組成:一組是隨各層輸入變化,另一組則是整體一致(不隨各層輸入改變)。計算式詳細如下
其中,是對最高維度操作,而則是可學的純量。動態組為,而則為靜態(誤差bias)。文章提到實務上n=4,其實比輸入本身的維度C通常是小得多。作者利用關掉特定mapping來測試模型表現,以評估哪一個mapping對模型貢獻最大。如以全矩陣為取代,以全1矩陣取代,和以identity mapping取代。得到結果如下。
可以看到是貢獻模型效益最多的。這個實驗標示了「提升訊息通道以進行交換」對模型的重要性,鼓勵往這個方向發展。
Res mapping的隱憂
如式(4)所示,在HC block堆疊之後,res mapping的連乘可能會讓計算結果變得不穩定。因為它和原本的identity mapping已經不同,訊息交換以後一定和原本的訊息複製品有偏差。也可以說,雖然得到訊息交換的好處,但原本residual block的基礎也被破壞了。
作者做了實驗,利用HC block堆疊產生的模型來測試穩定性,結果在損失的收斂上果然看到不穩定。這邊提早把mHC的實驗結果也放上來,和HC比較。

為了進一步評估對於模型不穩定的影響,作者再做了一個實驗。這個實驗分成兩部分:
第一部分,針對各個,以列為單位計算元素絕對值之和(row sum),並找到最大者,以抓到造成最大偏差的成員。原理為:因已標準化,所以。故,表示說在輸出中,某個方向會被放大倍數,其最大倍數為row sum的最大值。
第二部分,針對各,以欄為單位計算各元素絕對值之和,並找到最大者,以抓到反向傳播時造成最大偏差的成員。原理是反向傳播要倒過來看(),前向傳播看列,反向傳播看欄。
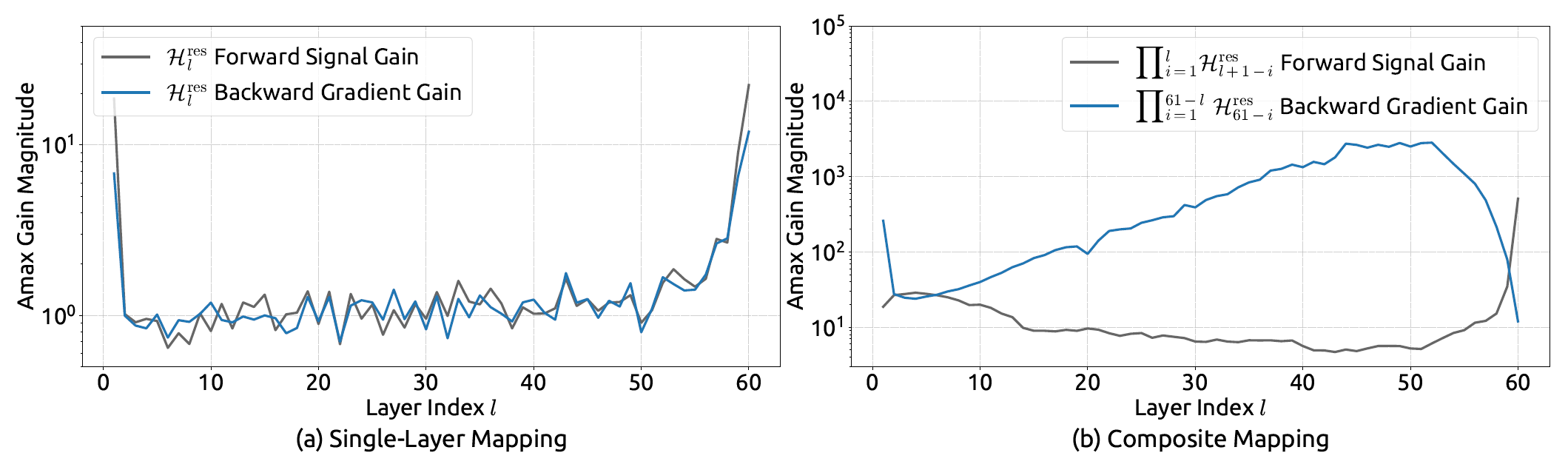
從上圖可以看到,在堆疊之後,累積偏差竟然可以高達3000,遠高於基本值1。因此連乘帶來的問題確實需要處理。
記憶體的隱憂
作者先針對單個HC block中,各計算動作需要的記憶體,做出一張表格:
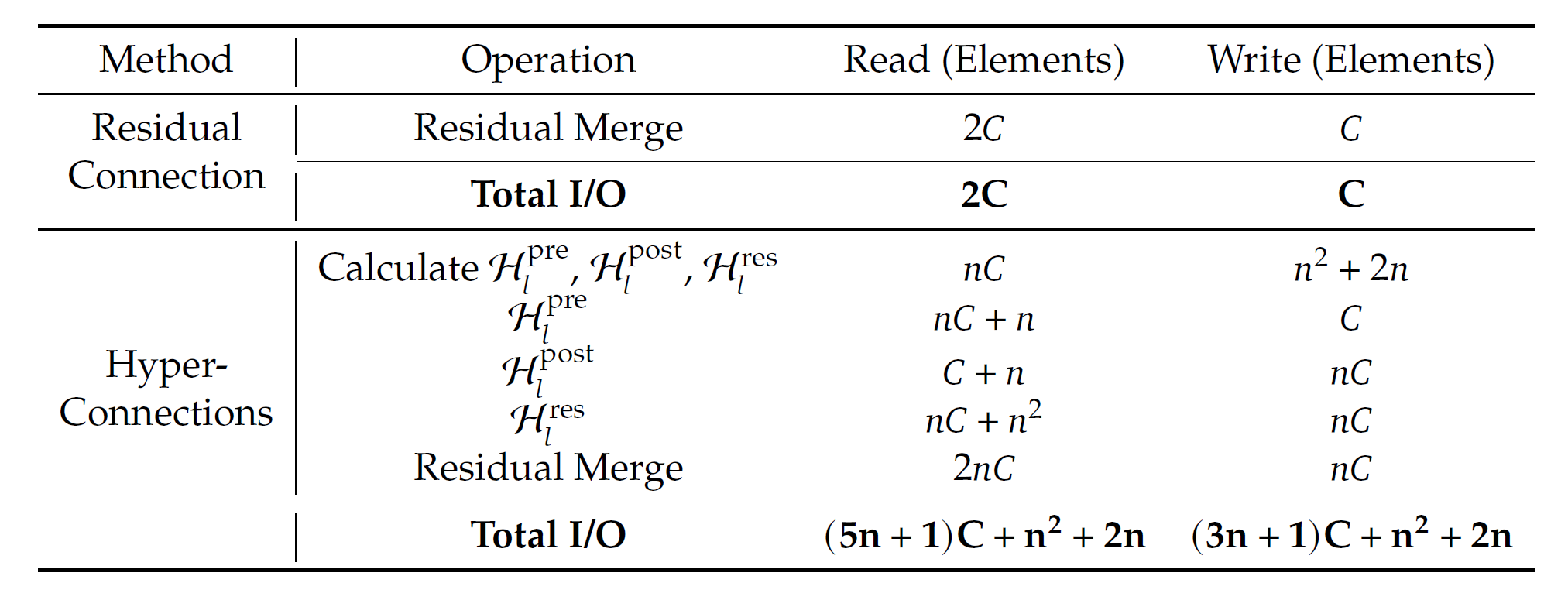
從上表可以看到,HC對記憶體的需求量,約為原本residual block的數倍,具體數值和n成正比。mapping本身需要藉由輸入x計算,然後再用mapping去和輸入相乘相加,以完成模型所需的計算。這些mapping裡面因為有需學習的權重,因此中間的activation(運算值)也都需要儲存,否則無法計算梯度進行反向傳播。這樣一來,記憶體佔用就多很多了。
盤點一下必須儲存記憶的地方:
- 正向傳播時:
- 各mapping產生的activation
- 訊息通道整合讀寫
- 反向傳播
這個問題甚至比前一個更麻煩。前一個問題只是讓模型不穩定,後一個問題是可能讓模型根本跑不起來。
mHC的應對策略
Manifold中文是「歧管」,即讓流體通過的管道。放到這裡的語境,指的是「能讓訊息流通的合法空間」。沒錯,所謂「合法」,就是有限制,相對於HC,它有去限制mapping,尤其是res mapping的變動範圍。
在identity mapping的時候,res mapping為,就是完全保留不交換資訊,實際上只有一條通道,也沒辦法交換。不過,這為多通道的限制提供一個方向,就是最基本而言,限縮在「1」可能有辦法維持穩定性。當然,如果要用HC,res mapping不可能是,所以要想辦法在能做訊息交換的同時,運算也不會越來越偏差。作者使用了雙隨機矩陣(doubly stochastic matrix),又稱為Birkhoff polytope,作為建立manifold的核心。
什麼是雙隨機矩陣?其實概念很簡單。隨機很好懂,就是變數。那雙是什麼?指行跟列。雙隨機矩陣必須滿足幾個條件:
- 矩陣內所有值為正
- 各行、列的元素之和為1
其實就是各行列的softmax。讓被限制到,把上述的條件寫成數學式,即為
當n=1時,通道數為1,矩陣只有一個元素,行列都為1,即為identity mappping。作者並補充說明選用雙隨機矩陣的幾個目的:
- 如上所說,這是一個正規化的矩陣,將矩陣的行列和限制為1,很大程度的避免了前向傳播相對identity mapping的運算偏移,以及反向傳播的梯度爆炸或消失。
- 承上,因為有限制,因此在連乘的情況下,也可以確保運算的穩定性。
- 雙隨機矩陣允許所有極端情況下的凸集合。這句話比較抽象,舉個例子好了。例如一個矩陣是
這是隨機矩陣的其中一個狀況。隨著模型學習調整,矩陣可能慢慢轉變,最後變成
學到把整個矩陣倒過來,這是另一個狀況。當然,也可能是在這之間震盪。上面提到的這兩個狀況,和這之間的震盪,就是一個集合。雙隨機矩陣可以把各種這樣的集合都包括起來,讓它本身儘管受到行列合為1的限制,但仍然能有很大的彈性空間調整權重。這就保證了資訊交換的可能,也間接確保模型的效益。
最後,作者提到,所有mapping內的元素都是全正值,以避免正負號相消,而無法實際確保不會發散的問題。可以想像,-99+100也等於1,但這不是作者要的。所以這也間接限制mapping內各元素只能在0-1之間。
參數化和mapping的產生
接下來,作者要正式把mHC裡面,各個mapping的數學式寫出來,就像式(5)中,HC的數學式表示。首先定義輸入:某一層的輸入,會先把它扁平化為向量以獲得完整的資訊。接下來的動作和HC很像:
其中,而。他們對應到HC裡的,是原始權重,此時還沒經過雙隨機矩陣處理。接下來作者要把mHC的成分加進去了。
指sigmoid函數。雙隨機矩陣,Sinkhorn-Knopp的具體操作方式如下:
- 先用指數對數把所有數值變為正
- 反覆做以下動作:
- 行正規化:把各行的和調整為1
- 列正規化:把各列的和調整為1
理論上,操作次數越多,越能接近雙隨機矩陣。本文作者把次數限定在上限20。
數學表示為
執行mHC的運算細節及基礎
首先當然是計算量的問題,這個是HC的另一個待解決問題。
合併計算,調整順序
在式(7)中,的計算會產生中間產物。作為產生mapping的前驅物()的必要材料,如果照式(7)的運算順序,不可能不儲存。然而,這等於要多存一份相當於大小的向量,對GPU無疑是負擔。而且,這個問題在HC就存在了。
幸運的是,在產生的過程中,和總是一起出現,而且他們兩個會先相乘,然後再去做其他運算(例如乘法、加法、非線性的運算等等)。所以作者就想到一個方法:讓直接和先相乘,然後才做RMSNorm。因為正規化只是把向量除以一個純量,這樣交換操作並不會有影響,卻不用再紀錄,取而代之的是紀錄,這個向量的大小只有,比起原本的自然小很多。
不僅如此,作者把所有的都合在一起算,所以會一口氣得到三個,同時也把和都合併成一個向量,一起計算。以下是整合之後的計算過程:
最後,再把mapping的部分做整合:原本的仍保留,將post和res mapping合併為,可以把元素讀取數量從降到,寫入數量從降為。如此,先解決掉一部分從HC以來龐大的計算量問題。
反向傳播時重新計算mHC路徑
上面提到的合併計算,只解決了一部分的問題,即正向傳播時activation佔據空間的問題。然而,反向傳播的問題還是沒有解決。為了學習mapping的權重,我們被迫至少要記、r、甚至是Sinkhorn-Knopp每一部中間的數值,否則無法得知mapping,因為mapping是從這些過程導出來,而非一個原生的參數。所以,如果我們要記住mapping,連帶要記住的東西實在是太多了。
作者處理這個問題的方法很簡單,也很暴力:在反向傳播時,重新算一次mHC的部分。如此一來,需要儲存的項目只剩下以下幾項:
- 最初的輸入(第一層,)。這是當然的,不然不可能運算。這項是前向傳播時就要儲存。
- 每層attention運算的結果()。這項是前向傳播時要儲存。儲存有兩個主要原因:
- 算力的消耗非常大,用算力換GPU的儲存位置不划算(畢竟最主要的函數運算是在這裡,不是在residual block)
- 即便不存,但也要記錄softmax的中間值,以及QKV的計算結果,其實少不了多少
- 每一層的輸入()。因為求梯度時,,必須有。這項是反向傳播階段,重新計算時需要暫存,處理完梯度之後就可以捨棄。
- ,這是mHC和F的共用節點。因為反向傳播時,它兩條路線都會用到,所以在重新計算時也要暫存,處理完梯度之後再捨棄。
- ,承4.,,因此重新計算時也要暫存,否則無法計算梯度。
全部需要的記憶體數量如下:
接著,就是執行面了。
硬體執行運算上的安排:搭配DualPipe
在進入論文提出的圖之前,要先有兩個認知:第一個是,除了計算前向和反向傳播使用microbatch,每一層的也是被打散的,即「同一時間可進行不同層的不同階段」,只是仍然在模型上保持順序。例如對於單一microbatch而言,在層的前向傳播還沒完成之前,層的前向傳播不可能開始。然而,對於不同microbatch而言,就可能出現在不同層,而非一定要所有資料一起過層之後,才能進到層。因此,有可能第個microbatch已經通過第層的MLP層,正在第l+1層的attention block(),而第個microbatch才正完成第層的attention block,準備進到第層的MLP層。這在反向傳播也是一樣的道理,只是順序反過來而已。
第二個是,DualPipe的設計,是為了讓每一層裡面的各分層(如ATTN、MLP)不會空轉,等待資料過來,而是盡量保持一直在使用(GPU)的狀態。因此,藉由排程,把各分層拆開,在同一階段,某一層的一個分層可能在處理一個microbatch的前向傳播,但另一個分層卻在處理另一個microbatch的反向傳播。對一個分層而言,可能上階段在處理一個microbatch的前向傳播,但下階段,下一個microbatch的前向傳播還沒到,所以他先處理來自另一個microbatch的反向傳播。
有了這些認知之後,再看論文的圖就比較好懂了。

值得一提的是,作者有說到,被單獨使用一個優先的串流處理,目的是避免卡住溝通串流。搭配上前面提到的重新計算和保留特定的幾個項目,整個前向和反向傳播得以被分解成許多階段,而散布在各個層同時進行,並不會卡住造成空轉。
以上就是DeepSeek mHC的介紹。實驗的部分嘛,當然他是比HC還穩定,成果看起來也比baseline更好,但我覺得關鍵還是在實際的表現,就和nested learning一樣。就看看過一陣子之後,DeepSeek實裝mHC之後的表現吧。
參考資料
- mHC: Manifold-Constrained Hyper-Connections. arXiv:2512.24880v1
- K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016a.
- Attention Is All You Need. arXiv:1706.03762v7
- D. Zhu, H. Huang, Z. Huang, Y. Zeng, Y. Mao, B. Wu, Q. Min, and X. Zhou. Hyper-connections.arXiv preprint arXiv:2409.19606, 2024.18