DeepSeek R1:GRPO
在強化學習,我們可以走多遠?
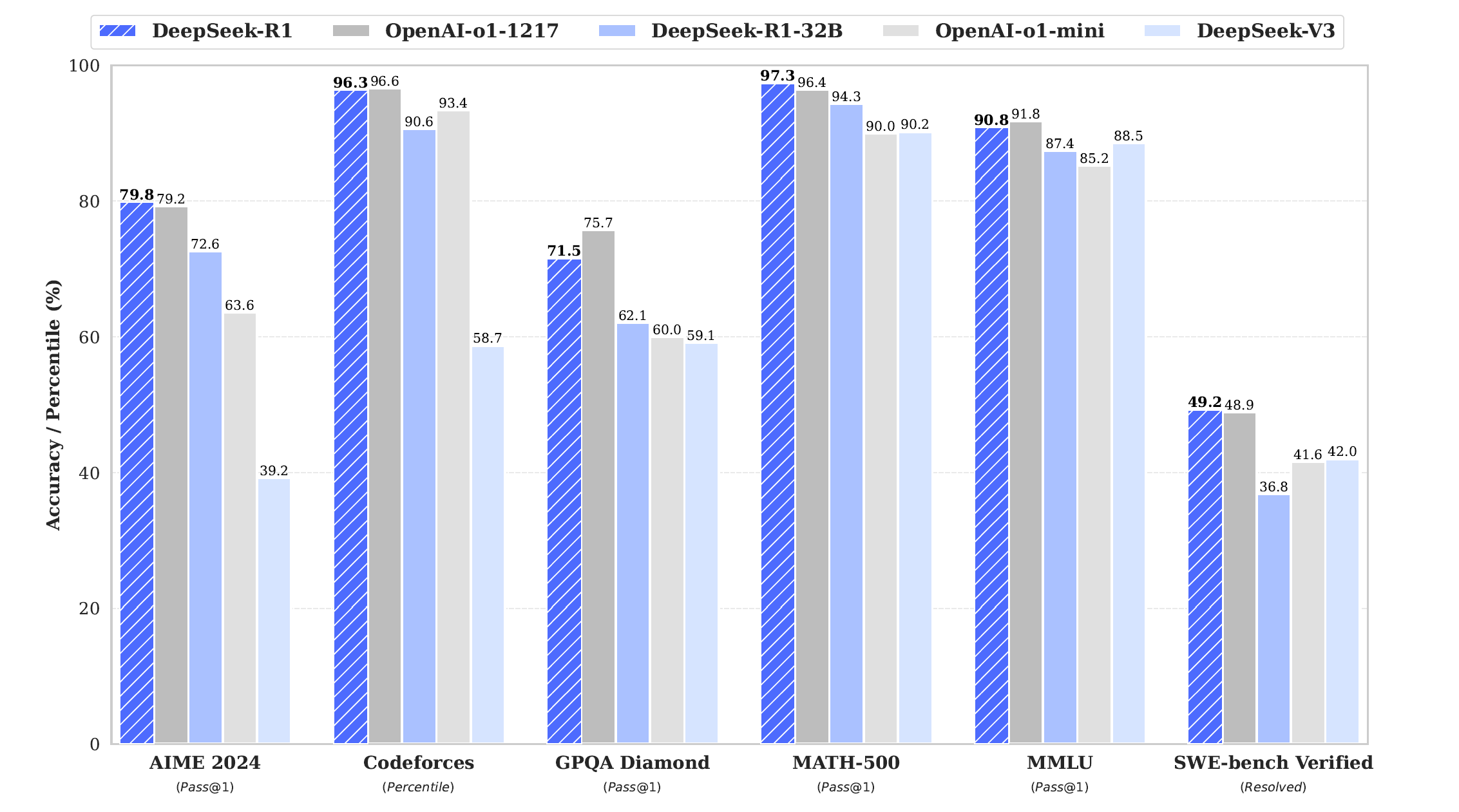
在前一篇V3的文章中,有提到R1[1]是相對比較專注在特定領域的模型,它的研究方向比較偏重於強化學習(Reinforcement Learning)。本篇的主題就來探討R1及其系列子模型,並試著整理強化學習在目前的發展狀況。
在進入正篇之前,先討論兩個觀念:後訓練和思考鏈。
後訓練(post-training)被日益重視
相較於預訓練(pre-training),後訓練著重在特定場域的使用。例如現在的LLM基本上都屬於預訓練模型,但我希望它能更好的發揮在病歷寫作上,於是我拿了一些既有的病歷資料來額外訓練模型,使它生成的病歷較能貼近我的需求。畢竟,不同醫院或科別,對病歷寫作著重的地方也略有不同。
雖然名為「後訓練」,但時間上其實還是在應用/部署(depolyment)之前喔!並不是指部署之後持續的利用校正的資料繼續調整模型的過程。
思考鏈(Chain-of-Thought)
這是個像魔法的東西。
2024年9月,OpenAI[2]推出新系列模型o1,將思考鏈的概念引入,搭配「強化學習」(增加訓練時間)及「增加思考」(增加測試時間),模型可以穩定的進步。這讓o1在專精領域問題的回答正確性有突破性的進展。比起同樣由OpenAI所開發的4o,o1在專精領域的成績幾乎可以用「輾壓」來形容。
那什麼是思考鏈呢?顧名思義,就是「思考的連續過程」。像人類一樣,模型在處理複雜的問題時,將其拆解成數個相對單純的步驟,並依序處理,最後得到答案。在這過程中,模型可以在每個步驟中尋找替代方案,而非擬定方案後就必須堅持執行完。更重要的是,模型會把拆解的步驟和流程顯示在回答中,因此人類可以觀察模型推導的過程,從而確定模型得到答案是依循正確的邏輯,而非漫無章法或隨機。因此它還帶有一些「可解釋性」的特性。
然而,OpenAI並不打算公開原始的模型推理過程,所以呈現在使用者面前的,已經是修飾過,模型認為是最佳方案的思考鏈。我們無從得知模型具體經過哪些流程,以得到這個結果;當然,也不知道詳細的實作過程。所以說,它是個像魔法的東西。唯一的線索是,OpenAI表示他們有「拉長」思考鏈的流程。
儘管如此,思考鏈的原理是有文章可考的[3]。在之前,思考鏈被視為是提示(prompt)模型輸出的一種方法。亦即,要求模型輸出時,必須帶出「輸入-思考鏈-輸出」的格式。模型基於要求,會把每一步驟的思考流程記錄下來,建立起關聯性,從而提高最終答案的正確性。基於注意力機制,從理論上來說也並非完全沒有邏輯。
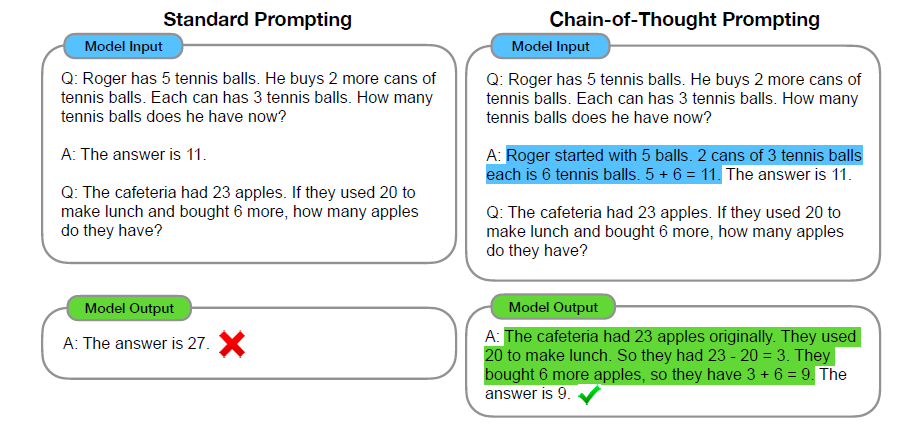
這樣的方式,讓LLM可以在很少標註資料的情況下,仍然表現不錯。這個資料可以是在訓練的時候提供(few shot),或者使用提示的方式提供(example)。
接下來我們進入正篇,看看R1到底做了哪些嘗試。
從V3開始:DeepSeek-R1-Zero
R1想要做一件事:讓模型在沒有任何標註資料的情況下直接開始任務,俗稱zero shot。模型必須依靠強化學習的方式自我進化,以達到目標。
Zero shot的相關介紹在
Group Relative Policy Optimization (GRPO)
這是DeepSeek開發出來的強化學習演算法[4],之前用於專精於數學推導的模型,現在則用在R1。他們首先打造一個專為數學任務使用的語料庫:DeepSeek Math Corpus,內含1200億(120B)的數學相關辭彙的token。接著,基於該語料庫,DeepSeek開發出DeepSeekMath-Base,是從生成程式碼的模型訓練過來的。訓練過程裡面,GRPO被認為可以減少所需的訓練資源,並提供更好的結果。
強化學習的基本原理為:建立一個獎勵模型,用於回饋LLM的輸出是否符合需求,建立LLM選擇生成文字的「策略」(policy)。而強化學習的演算法則使用這些獎勵模型,來協助訓練LLM。由於文字生成的結果符合需求與否,比起一些有標準答案的任務,是相對主觀的,牽涉到喜好、文意通順、是否圍繞中心思想等等,因此訓練獎勵模型的時候必須相當程度的參考人類的回饋,根據回饋來給生成文本打分數,因此有不同的獎勵讓獎勵模型調整LLM。
GRPO是Proximal Policy Optimization (PPO)的一種變異型,這邊把它和幾種比較有名的強化學習演算法做比較[5]:
PPO [6]
基於策略梯度法(policy gradient,PG),或演員-評論家法(actor-critic,AC),本質上是用兩個深度網路,一個(主網路)根據當前狀態和行動的回饋隨時調整參數,另一個(目標網路)則是過一段訓練時間,再根據主網路更新的參數逐步且緩慢的改進。
強化學習的精髓在於損失函數的設計。PG或AC的損失函數為:
PPO強調策略更新的速度不要過快,因此它不是直接使用,而是用和的比值,即更新參數前後網路輸出,對於特定狀態採特定行動的機率之比。此外,再使用兩種方法(二者擇一):
第一個是「信賴區間」設定,把比值限定不得超出一個範圍,若超出,則強行以該信賴區間的上下限取代之。這個方法稱為CLIP。損失函數為:
第二個是利用KL divergence,降低比值過大的風險。這個方法稱為KL penalty。損失函數為:
d為 KL divergence的期望值,d_targ為目標網路KL divergence的期望值。
具體訓練獎勵模型方式為:
- 計算分數:利用主網路和目標網路計算各個文字的分數及優勢函數
- 更新主網路參數:可每個字計算分數和優勢函數,就利用損失函數更新主網路參數,或者累積一定字數再更新亦可
- 更新目標網路參數:累積一定訓練批次後,將主網路參數同步到目標網路上,回到步驟1.
- 訓練完成:依梯度下降收斂程度,或資料訓練完畢決定
Direct Preference Optimization(DPO) [7]
採用完全不同的思路,捨棄強化學習中另外訓練獎勵模型的概念,將人類回饋的喜好直接反映在LLM上面。其損失函數為:
翻譯一下它的精神:讓模型多輸出回饋中喜歡的答案,減少輸出不喜歡的。利用比值,降低更新的速率。因為本篇主要探討GRPO,所以這部份就不著墨太多,或許之後再開一篇文章討論。
GRPO [4]
- 原則上是從PPO衍伸而來,比起PPO,GRPO做了幾個改動:
省略Value function,或critic評論家神經網路。在PG或DQN,第二個神經網路被稱為目標網路,到了AC,第二個神經網路被稱為critic。其數學意義上的角色略有不同(DQN是為了計算Q值,AC是為了計算價值,源於PG with baseline,用價值函數代入baseline)。無論如何,GRPO把這個網路省略了,取而代之的是用參數未更新前的舊版神經網路,並以批次預測多個輸出的平均來更新神經網路 - 合併PPO兩個更新參數的策略,同時使用clip和KL divergence
- 更改優勢函數計算的方式
GRPO的損失函數為:
優勢函數修改之後,不再需要計算價值函數,而只需要獎勵r。而policy-based的模式本來就不須計算Q值,所以只需要一個神經網路就好了。
等等…誰說這個獎勵模型是神經網路的?PG或AC是神經網路,但GRPO不是。
獎勵模型
DeepSeek-R1-Zero使用的是基於條件式的獎勵模型(rule-based),條件如下:
- 正確性模型:對於有正確答案的題目(如數學或程式設計),模型被要求以固定格式輸出答案,以便進行校對和執行。
- 格式性模型:對於推理型的題目,模型被要求把思考過程條列在固定的格式。答案歸答案,推理歸推理,各自區域分明。
這些概念也都用在DeepSeek V3上面。為什麼不用神經網路式的獎勵模型呢?因為怕reward hacking — 模型會利用演算法的「漏洞」得到最大獎勵,但並沒有真的學到該學的 — 就像CNN在還沒有Grad-CAM之前,很難確保它特徵萃取的依據是人類希望看到的視覺分布。在大尺度的強化學習訓練時,很難避免這個現象的發生,但要重新訓練獎勵模型又需要大量資源,因此他們決定直接使用條件式模型。
表現
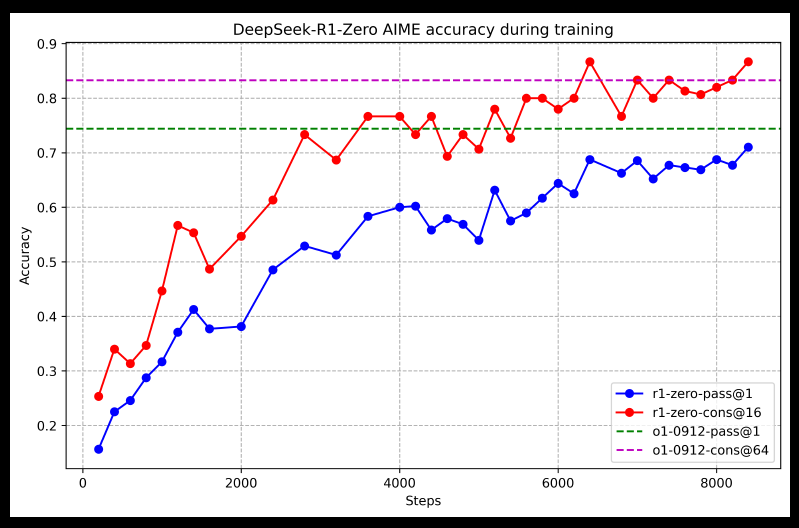
DeepSeek-R1-Zero在不使用資料微調參數,監督式學習的情況下,就展現相當出色的推理能力。如果搭配「多數決機制」,即讓模型對單一問題輸出多個答案,然後選出出現頻率最高的答案作為其輸出,則正確度可從71%提升到86.7%。
他們讓DeepSeek-R1-Zero從初始模型,直接使用強化學習的方式自我訓練。這中間沒有使用任何後訓練資料。可以看到隨著訓練時間,模型的表現穩定的進步。類似的狀況在OpenAI拉長思考鏈的做法也有出現,但兩者運用的概念不同。
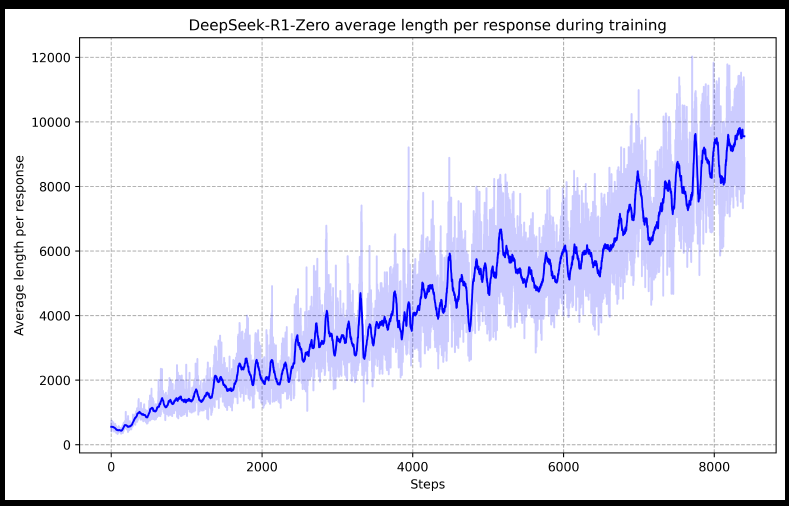
同時,DeepSeek-R1-Zero在回答問題的過程中,還展現出回顧前面做法的能力,這個能力展現出模型如何和強化學習環境互動。接著就是讓人很難相信是不是真的,但不只這篇論文提到過的「靈光一現」時刻(aha moment)。在經過一定程度的強化學習之後,模型知道利用較長的時間,回顧前面的步驟,會改善回答問題的能力。因此,會發生模型在進行一段時間的推理之後,似乎自己打開了思考的窗口,進一步突破到得到答案,或接近正確答案的邊緣上。

不過,DeepSeek-R1-Zero也被發現一些缺點,其中最大的問題是可讀性,以及不同語言的混用。為了改善這個問題,作者群利用強化學習建立一個模型,以探索cold-start data,即較缺乏過往經驗或歷史,可以拿來借鏡回答的資料。不過這些資料有挑選出對人類還是比較容易回答的,以便評估模型表現。這個模型就是DeepSeek-R1。
DeepSeek-R1
DeepSeek-R1被賦予兩個任務:一是想嘗試利用高品質、少量的資料,讓模型從無到有的快速上手任務;二是打造一個對使用者友善、能有清楚、專一的思考鏈,又能勝任一般任務的模型。他們展開了四個階段的建構流程,以下陸續說明。
利用資料幫助模型快速推進前期
想要避免DeepSeek-R1-Zero在訓練初期,強化學習進展緩慢的困境,作者使用一些資料來微調模型,當作強化學習初始的基礎。這些資料都是由模型生成而來,包括:用提示的方式舉幾個常思考鏈的例子、用提示的方式直接告訴模型產生具有回顧和驗證的思考鏈、將DeepSeek-R1-Zero產生的結果改良成可讀性較高的格式,以及由人類標註來精煉資料。這些資料用來微調訓練DeepSeek-V3為基礎的模型。
這個方式讓DeepSeek-R1在可讀性及發展潛力上優於DeepSeek-R1-Zero,尤其是可讀性,DeepSeek-R1會把思考過程和總結很明確的列出。
推理導向的強化學習
這個階段在DeepSeek-R1-Zero也做過,就是利用一些有標準答案的問題(如數學、程式、科學、邏輯推理)來增強模型的推理能力。但在這邊,語言混用的情況又出現了,因此不得不做調整。
調整的方式是在獎勵模型的部分額外加入語言項目:依據想要的語言佔據思考鏈的比重給分。這個項目和推理本身的正確性加總,得到最終獎勵。利用這個方式,模型雖說有稍微降低表現,但因為可讀性大大增加,主觀上對人類比較友善。
擴大訓練
在推理導向階段的訓練接近收斂時,他們把額外的資料加進來,主要是擴展模型對其他面向任務的能力。
- 推理型資料:在這個階段,有些資料不再能用條件式獎勵模型,而須使用生成式獎勵。部分資料甚至是把標準答案和模型預測的結果丟回給DeepSeek-V3做判斷。這部分的資料,過濾掉語意不清、段落過長、語言混用等品質不良的資料後,剩下約60萬筆用來微調訓練。
- 非推理性資料:例如角色扮演、寫作、翻譯等等,主要以之前DeepSeek-V3的訓練流程和資料直接拿來使用。部分資料會要求DeepSeek-V3表現出較長的思考鏈。這部分資料約20萬筆。
DeepSeek-R1在這總共80萬筆資料訓練兩個周期(epoch)。
在廣泛任務的強化學習
承接上個段落,模型在第二階段的強化學習主要在提升模型的「幫助性」和「無害性」上。這兩個也是當前LLM或AI一直在探討的倫理範疇。
在幫助性上,主要看模型的總結是否足夠有用,是否有針對到問題回答,以及避免過多思考鏈或推理的過程,呈現在總結的地方。至於無害性,則必須審視推理過程和總結,排除掉任何可能有潛在危害的元素。這個部分牽涉到人文和政治,其實是很主觀的,也已經不在單純的數學或科學範疇裡面了。
但使用者是人,所以這部分其實非常非常重要,只是不在本篇文章的探討範圍裡。
模型蒸餾
為了驗證擴大訓練的效果,作者群用80萬筆資料去微調包括Qwen、Llama等模型,並蒸餾出較小的模型架構,總共有6個。蒸餾模型的過程中並沒有使用強化學習的技術。
成果
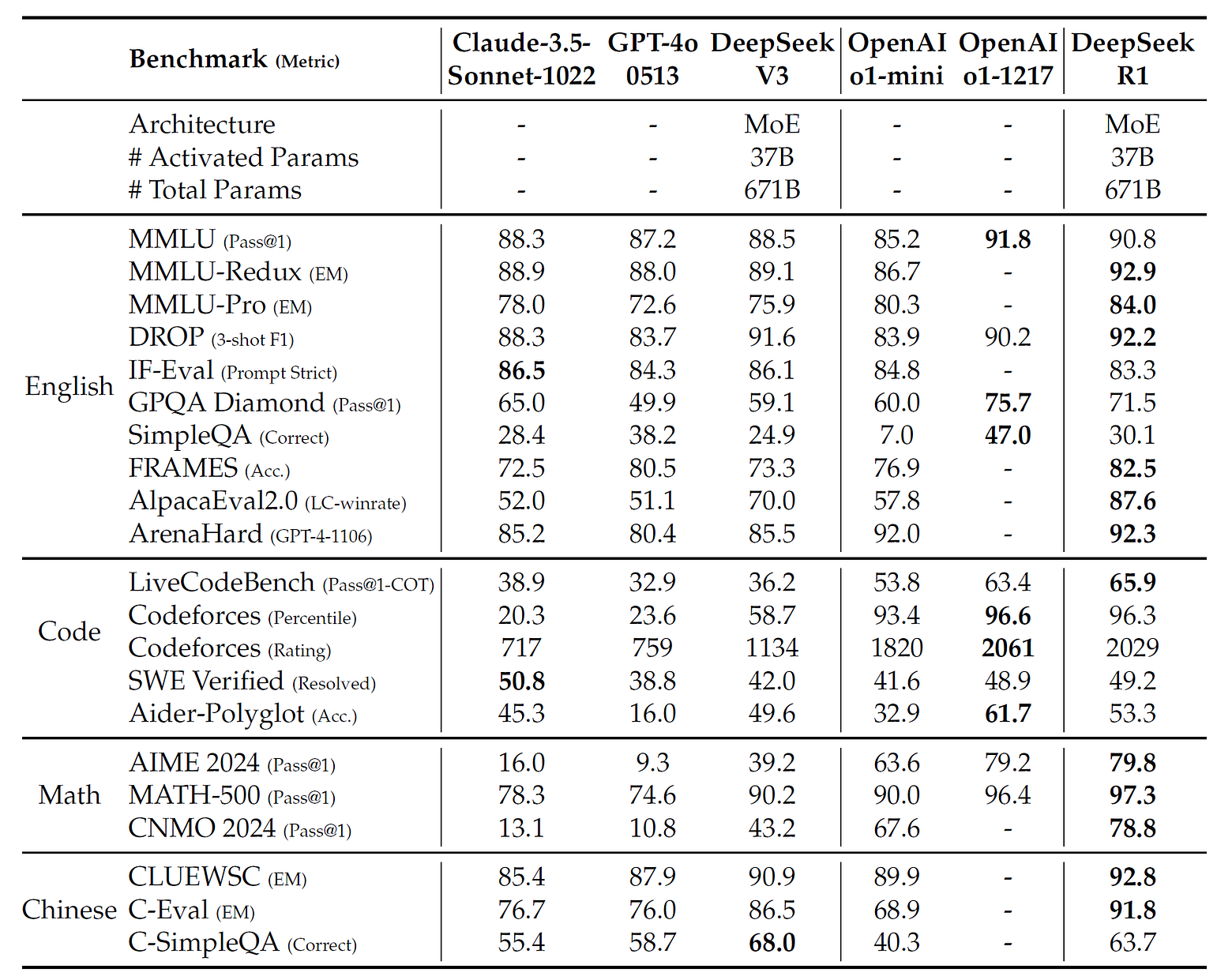
在推理性任務,DeepSeek-R1確實展現出相當強大的能力;比較有趣的是在最下面一列C-SimpleQA項目,DeepSeek-R1表現是低於DeepSeek-V3,但作者群表示這是因為DeepSeek-R1基於強化學習的「安全性」機制,拒絕回答某些問題。若把這個機制拿掉,DeepSeek-R1的準確性可達超過70%。這部分就留給讀者自行去想像。
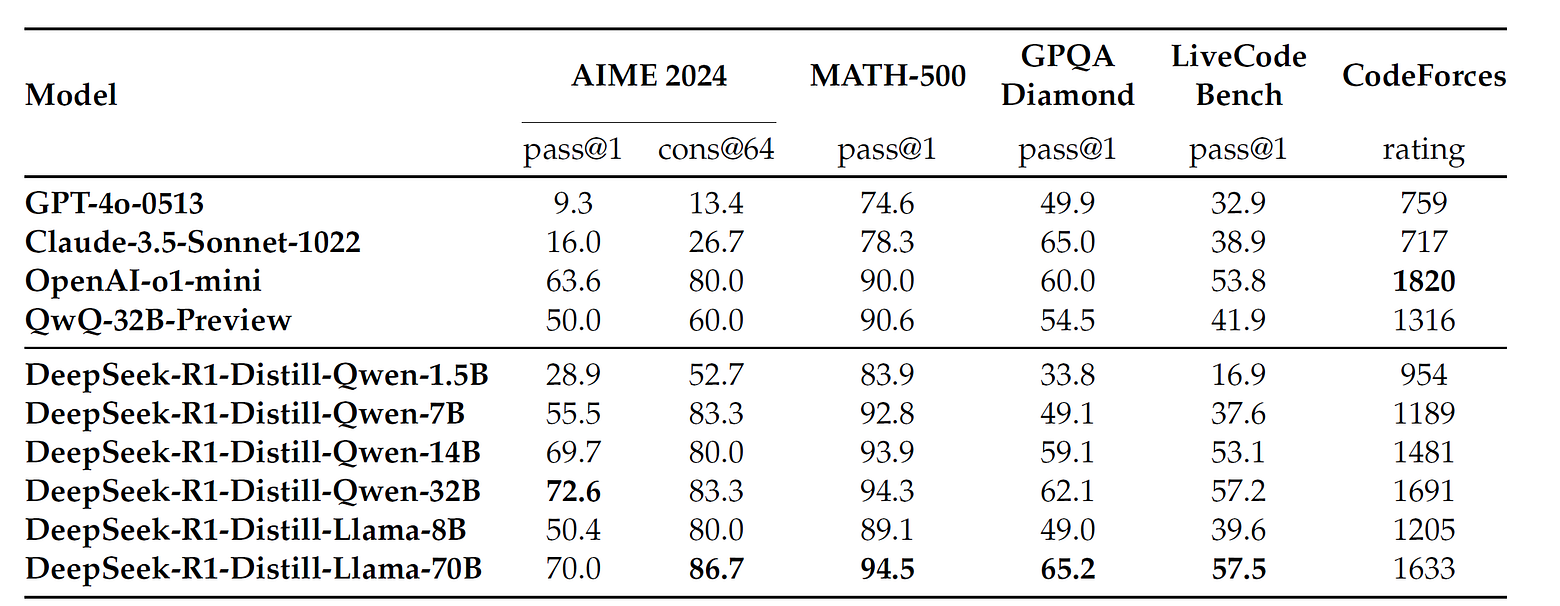
蒸餾模型的部分,算是強力的展現了效率,即用較少的參數取得較好的效果。
結論
DeepSeek-R1系列的模型,確實在強化學習運用在LLM上面提出了貢獻。在R1-Zero,模型嘗試使用無標註資料的情況下,純粹用強化學習「自我進化」。在GRPO演算法和條件式獎勵的組合下,模型雖然取得一定的成功,但受限於可讀性的問題。
因此到了R1,使用一些資料作強化學習的基礎,搭配針對在R1-Zero遇到的問題做修正,模型在推理類型的問題有長足的進展,同時還能兼顧可讀性。當然,由於一般型任務大部分借重V3,R1在這部分的表現就未必優於V3。兩個模型確實各擅勝場。此外,蒸餾的模型則展現了資料微調訓練(supervised fine-tuned training,SFT)的成果。
終於把兩篇長論文都看了個大概,也可以收束這個討論串了。為了這兩篇論文,又讀了不少額外資料以增加理解論文所需的背景知識,算是額外的收穫。之後或許可以再開一個強化學習系列出來?
謝謝看到這邊的各位。
Reference
[1] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,DeepSeek-AI
[2] Learning to reason with LLMs. OpenAI. https://openai.com/index/learning-to-reason-with-llms/
[3] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903v6
[4] DeepSeekMath: Pushing the Limits of Mathematical
Reasoning in Open Language Models. DeepSeek. arXiv:2402.03300v3
[5] https://anukriti-ranjan.medium.com/preference-tuning-llms-ppo-dpo-grpo-a-simple-guide-135765c87090
[6] Proximal Policy Optimization Algorithms. https://arxiv.org/abs/1707.06347
[7] Direct Preference Optimization: Your Language Model is Secretly a Reward Model. https://arxiv.org/abs/2305.18290