DeepSeek V3技術報告
不能說抄襲,但也不是革新
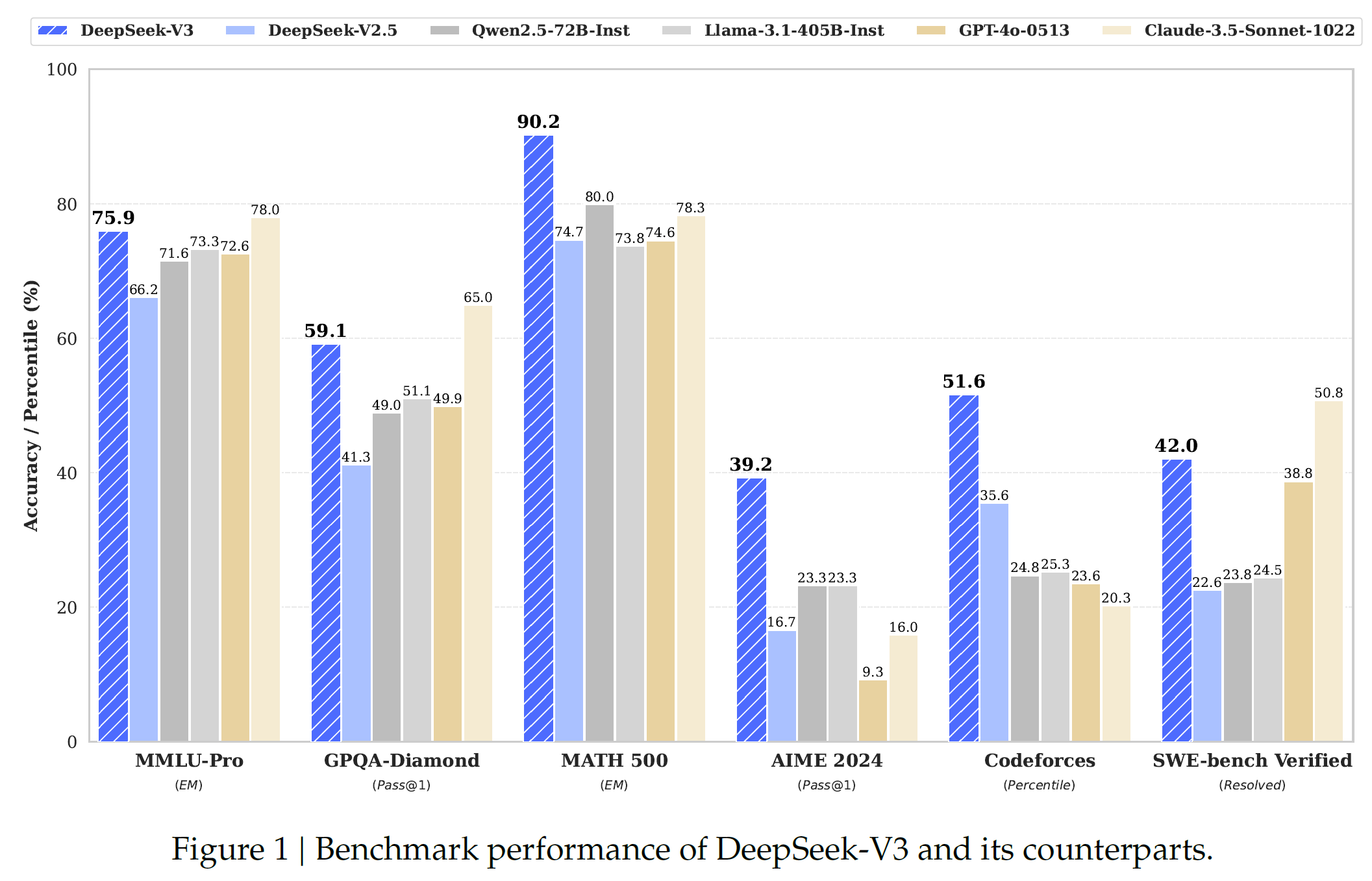
2025年過年期間,兩個模型橫空出世 — 實際上在圈子裡面,也已經醞釀有一個月了 — 中國DeepSeek公司推出兩個大語言模型,DeepSeek V3和DeepSeek R1,標榜「開源」、「節省」、「高性能」、「展現推理思考過程」等特色,並引發一系列激烈的討論。本篇和下一篇文章將從其公司發布的技術報告分別探討這兩個模型,並整合一些網路上看到的意見和資料,試著提出自己的看法。
本質上仍是大語言模型,並沒有跳脫
在進入技術報告(technical report)之前,先奠定一些大觀念。首先,DeepSeek公司自己也表明,這兩個模型仍使用Transformer為基底[1],即注意力機轉(attention)。這個由Google於2017年提出的基礎技術,至今仍深遠的影響自然語言模型,甚至已經跨到電腦視覺領域,從而對整個人工智慧的技術帶來重大的改變。相關已經有很多文章介紹了,但我發現自己從來沒有針對這篇論文作筆記,或許之後應該還是要回來補上,但就不再這邊多著墨,以免模糊焦點。
順帶一提,為什麼中文在兩年前突然出現「生成式AI」這個名詞?因為GPT。GPT的全名是什麼?Generative pretrained Transformer。沒錯,他也是基於Transformer的模型。中文全名為「生成式預訓練transformer模型」。
DeepSeek V3和R1的方向略有不同
這其實是兩個不同訓練方向得到的模型成果。V3主打多專家混合(Mixture of Export,MoE)、多目標預測式訓練(multi-token prediction training objective)[2]以及FP8訓練。其部分成果,尤其是MoE,源自於更先前訓練的V2模型。所以V系列有自己的發展科技樹。
R1[3]則是聚焦於使用強化學習(Reinforcement Learning),而且使用的是非監督式微調(supervised fine-tunning)的作法,目的是評估減少專家人力的可行性。這過程有遇到一些障礙,在R1,他們提出一些方法來試著解決問題,並產生R1-zero、R1、以及基於Qwen and Llama,從R1蒸餾出來的六個大小不等,但都算是真的相當小參數量的子模型。
到底V3和R1有沒有關係呢?有一點點。雖然V3的訓練時間早於R1,但在後訓練階段時,V3有引入來自R1的推理能力,例如思考鏈(chain of thought)[1]。
網路上已經有V3和R1的許多整理比較[4],這邊只說綜觀的:V3比較偏向綜合性、一般化的使用場合,例如初學者詢問程式設計的基礎、或者一些專業領域的基礎背景知識等等,類似Google搜尋;而R1就偏向於專精領域,基於某個特定任務的需求,例如解題、思考一些該領域目前有初步突破,但仍未解決、甚至尚未有頭緒的問題等等。這是基於其模型訓練的方向、以及設計模型的人為模型設定的目標所得出的,並非模型本身完全具備這個能力,因此其實都不應該過度依賴模型。
說了這麼多,那我們進入本篇的重點,V3看看吧。
模型運作架構
這邊分成三部分:隱藏式注意力(latent attention)、專家混合、多目標預測。
隱藏式注意力
注意力機制[5]在原論文中即提到,其QKV在進入attention機轉前
有各自先投射到一個指定維度的空間。
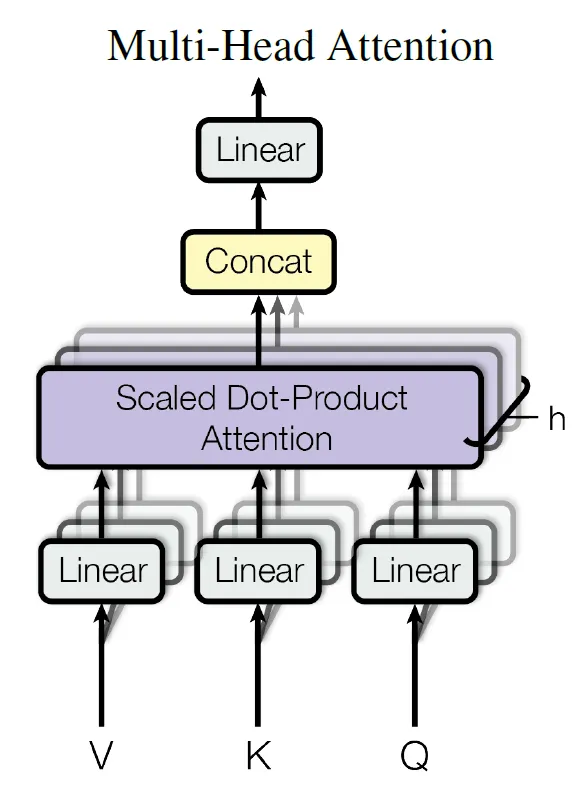
在DeepSeek V3,進入attention之前先把輸入各自乘上不同的權重,其維度對應Q和KV的維度,產生兩個潛藏向量:一個是Q的維度的,另一個是KV維度的。接著,引入Rotary Positional Embedding (RoPE)的概念,對Q和K進行RoPE處理。
那什麼是RoPE[6]呢?最簡單的說,可以把它想成模型會知道Q和K的絕對位置,和transformer只有在計算attention時才知道QK的相對位置關係不同。具體做法則牽涉到利用共軛複數和複數平面圓周投影(所以才有rotary這個字)的原理[7],就不仔細說明了。知道絕對位置之後,模型可以不必仰賴attention的矩陣來操作QK相對位置編碼,因為他已經知道絕對位置了,所以直接就可以編碼相對位置。好處是計算速度會比較快。
Q的部分兵分兩路:Q的隱藏向量一組經過RoPE內積,另一組沒有,然後串接起來。K也有兩組,一組來自於輸入向量直接乘以K維度的權重,做RoPE;另一組來自於KV隱藏向量,沒有經過RoPE,然後也串接起來。V則是從KV隱藏向量而來,沒有經過RoPE。這樣各自完成前置準備之後,才開始進入attention計算。
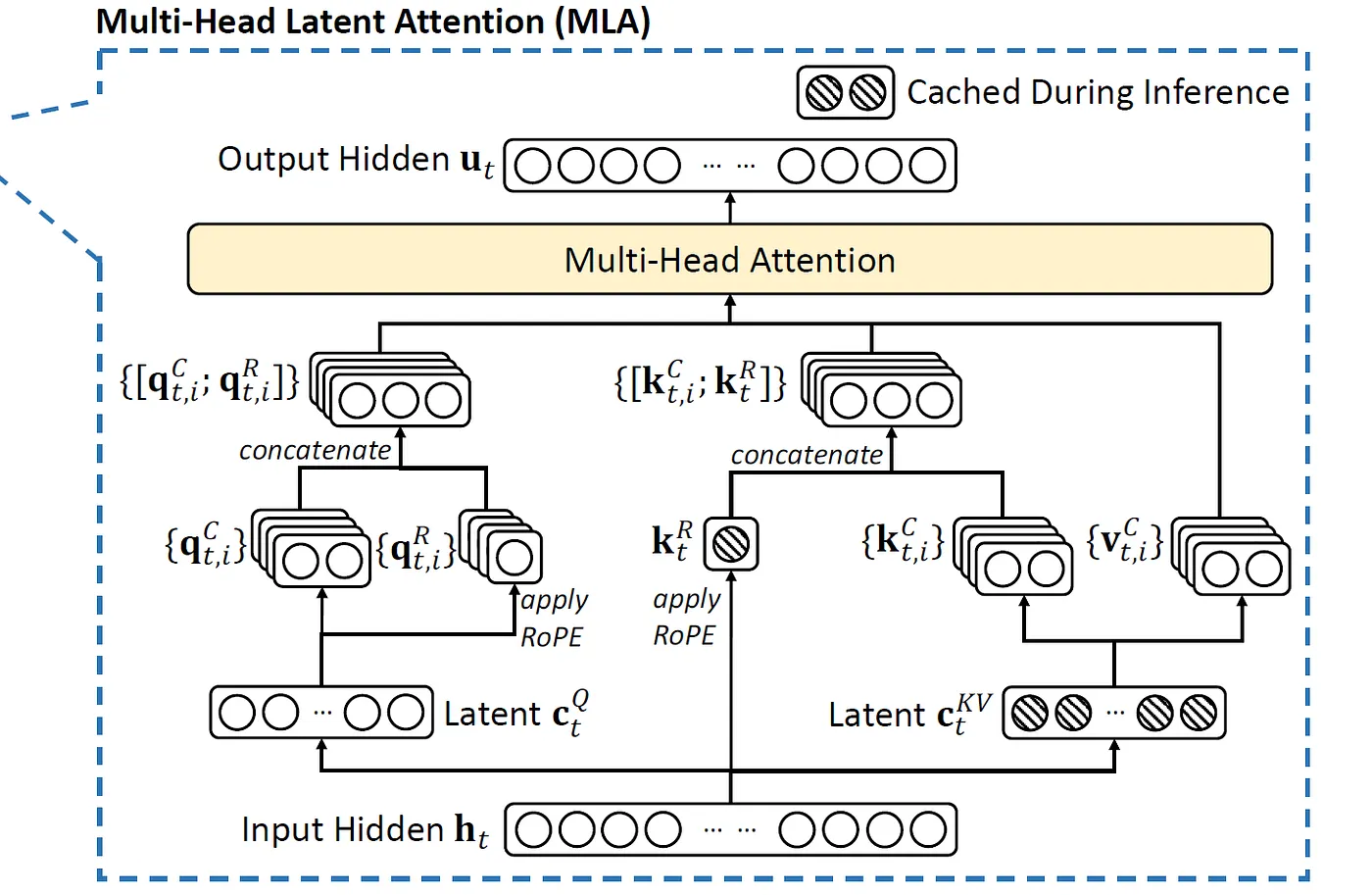
隱藏式注意力的關鍵是潛藏向量。潛藏向量的維度遠小於輸入向量,目的是將KV間的注意力張量壓縮,並在模型進行預測(inference)時放入快取,達到加速效果的同時,仍能維持好表現。Q的潛藏向量,則可以減少訓練時記憶體的消耗。
結論:潛藏式注意力可以降低訓練記憶體消耗,並在預測時降低時間消耗,但不會降低模型表現。
專家混合
與其說是專家,不如說是分片 — 把整個模型拆成很多片 — 當有輸入進來,根據關聯性找對應片區的模型來處理。只是有時候,每一片區的權重可能剛好對應某個擅長的區域,就像專家一樣[8]。
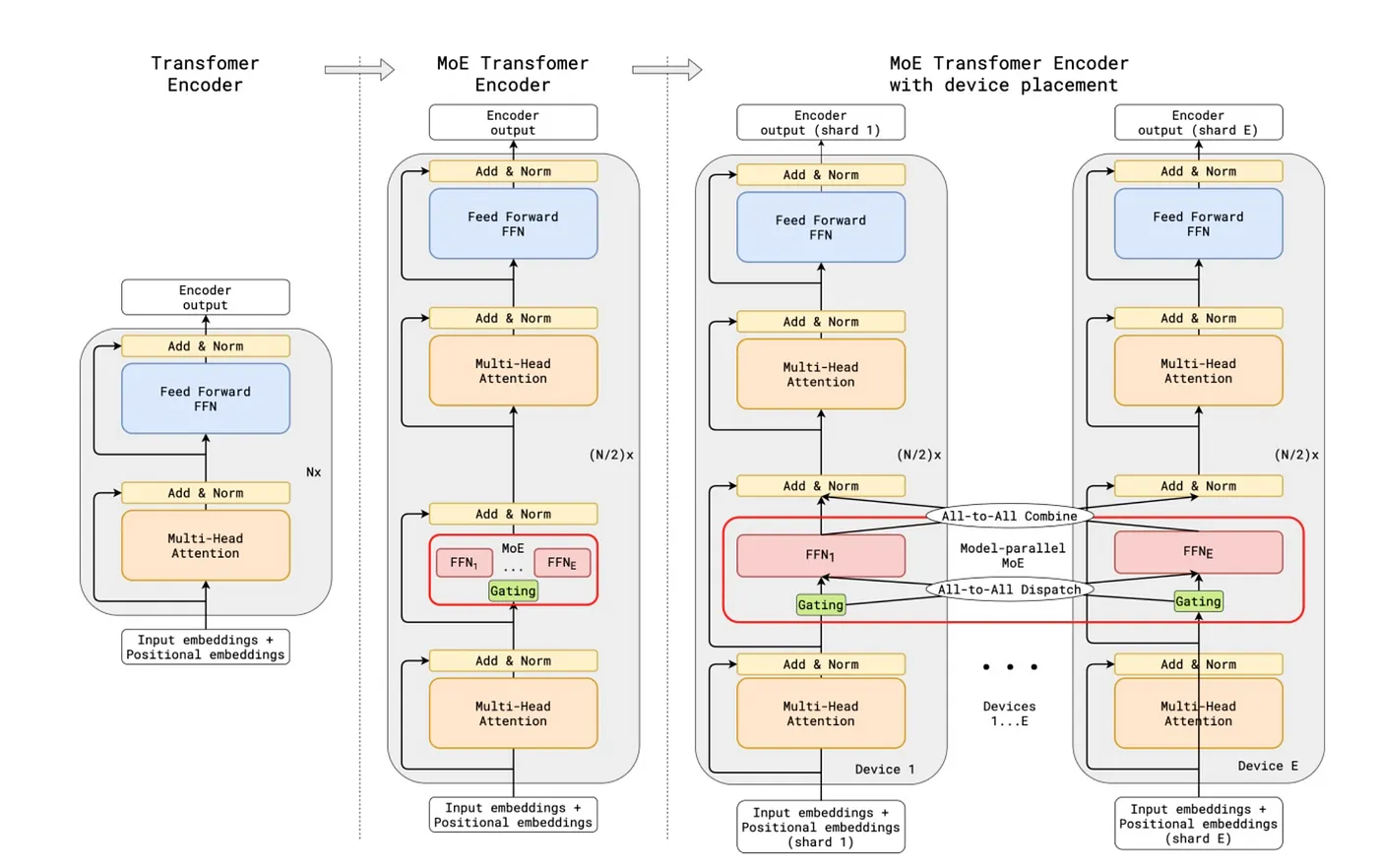
這裡關注的點是feed forward的地方。在每兩個feed forward層,替換成MoE層:訓練資料會被分成很多份,每部分會啟動對應區的MoE層,進而進入到其後的attention層。這個對應關係是需要訓練的,因此有一個損失函數專門評估對應關係:auxillary loss。目標是讓每個分區都能均勻的處理資料,而不會過於側重在某一區,這樣MoE的價值就不見了[9]。
在DeepSeek V3,MoE被做了一些改良:他將分片區做的更多,使資料分配更精細。此外,將部分分片區獨立出來,作為通用區,就是允許這些分區處理超過一個部分以上的資料。在auxillary loss上面,他將損失函數加了一個bias,做為評估路徑之用。在訓練過程中,他會因應分區的均勻度,對各個分區增減。DeepSeek認為這樣做之後,分區的均勻性比使用單純的auxillary loss更好。
結論:MoE可以讓模型平行處理資料,預測更有效率,而且能實現多機器並行運算。
多目標預測
NLP模型的訓練過程,一直都是以「蓋住句子中的某個字,讓模型預測」的方式為主軸。利用這個方式,模型學習到句子中文字間的相關性,據此判定文字之間該如何串聯。舉個實際的例子:
我看到__騎在腳踏車上。
模型就要去預測這個空格要填什麼。首先,要知道「騎」這個詞是動作,所以前面的字大概率是一個生物,不會是死物。所以騎和生物之間的關聯性,比和非生物還要高。再者,因為騎這個動作屬於高意識、高精細度的動作,所以可能是至少具備一定靈活度,而且腳要比較長的生物才有辦法勝任。因此,貓、狗和騎的關聯性可能低於猴子或人。…諸如此類,可以建立出一些字詞的相關性。
預測某個單字的訓練方法,就是單目標預測。這樣的訓練方式有一些弱點[10]:
- 效率低。因為需要一個字一個字預測,如果要產生較長句子甚至文章時,時間會拉長。當然,消耗運算資源也會增加,因為是串聯式的。
- 語意理解被侷限在較區域的範圍,要產生一個對於整個格局充分掌握的文章較困難,雖然注意力機制已經讓這部分有很大的進展。
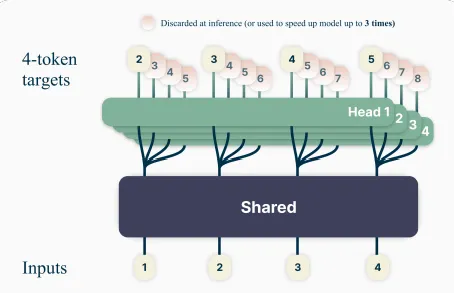
多目標預測就是基於這些弱點所提出的改良方案[11]。其精神就是讓模型同時預測多個單字,而非一個。從圖四可以知道,雖然一次預測多個目標,但他們是共用一個注意力機制基礎(attention trunk)的,而非各自為政。在注意力機制將輸入文字轉成萃取張量(representation)之後,再根據不同的預測位置分出不同的head,一個位置有四個head,產生四個預測值。訓練時會利用multi-head的輸出來校正模型,但實用時只取第一個head的輸出當答案。
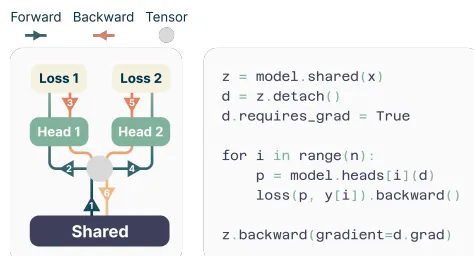
為了避免記憶體的佔用,每個head的梯度會依序處理(依照傳播=>反向傳播的順序),並將其累積在注意力機制基礎(trunk)的地方。等到head的梯度都處理完之後,再把梯度沿注意力機制基礎的結構反向傳播。整個過程用圖五表示,也有Pytorch的pseudocode可以參考。
多目標預測的優勢,最明顯的主要是在訓練和實用的速度。當然,記憶體消耗的問題也有做改良。此外,因為一次預測多個字,在預測目標範圍內的位置之間會有交互作用,反映在注意力機制基礎的權重分布就是,對每個預測位置,權重未必同等重要。
DeepSeek V3在多目標預測做的調整是順序性預測,亦即和上面論文提到的同時預測多個字不同,而是依序預測。更具體的說,即是預測其中一個位置的字時,不僅只參考來自注意力機制基礎的萃取張量,而且還參考前面幾個預測位置的輸出以及張量。
結論:多目標預測可以讓模型更有效率,而且讓模型的視野更廣,更有能力掌握整個文章或較長文句的展現,維持描述的一致性。
模型訓練架構
先講三個概念當作背景知識,都跟平行處理有關[12]:資料平行處理(data parallelism)、模型平行處理(model parallelism)、流程平行處理(pipeline parallelism)。
- 資料平行處理:同一個模型復刻在不同的GPU上,把資料拆分之後在不同的GPU上進行處理,計算梯度之後累積起來。弱點是要把每個模型都複製到GPU上,因此模型架構不能太大;此外,GPU記憶體也要夠大,才能儲存整個模型。
- 模型平行處理:把模型拆分成子架構到不同GPU上,各自可以處理來自外部的資料,同時模型子架構間也能交換資訊。這樣可以降低模型架構和GPU記憶體的限制,但要如何建構GPU之間的聯繫則是一項挑戰。另一個問題是,假如是用在有順序性的模型架構,那資料通過子架構處理之後,在下一批資料進來之前,該子架構會閒置。這樣會降低GPU使用的效率。
- 因應模型的特性,可以使用在具有順序性的架構,如RNN,或者需要平行展開的架構,如CNN模型最後的full connection layer。事實上,最早提出這個想法的,是AlexNet的作者,他發現CNN模型在CNN部分,資料比參數多,而在全連結部分,參數比資料多。因此,他想到在CNN部分,可以用資料平行處理;而在全連結部分,則使用模型平行處理。
關於AlexNet,可以參考這邊(上)、(下)。其實模型架構上就有常識一些平行處理了,只是在那個年代,GPU還沒這麼強力,差異不明顯。
- 資料和模型平行處理合併使用,則可以進一步縮小輸出規模,但也要看實際上對資料輸出的要求是什麼。如果資料輸出要求的規模大,那這樣的平行處理就需要夠多的單元,才能拼湊出符合需求的規模。那限制就不是在硬體本身上,而是數量=錢。
- 流程平行處理:基於模型平行處理的想法,把資料拆分成更精細的片段(micro-batch),可以確保GPU有資料處理的時間增多,提升效率。這裡有一個問題是:權重的更新必須在一整組micro-batch都跑完、梯度也傳播完之後才更新。那中間每個micro-batch計算的結果都必須暫存,就會增加記憶體消耗。
- 因此,在這支上提出一個方案(1 forward 1 backward):在第一個micro-batch到達最後一個子架構之後,不要馬上讓這個子架構接第二個micro-batch,而是先反向傳播第一個micro-batch回去,然後再接第二個micro-batch。這樣一來,第一個micro-batch就可以先反向傳播回去更新權重,不必等其他micro-batch都正向傳播到底之後才出發。不過,這樣做仍然無法解決子架構閒置的時間問題。

- 將每個micro-batch再細分階段投入,就能再減少子架構閒置的時間。這個方法衍生的問題是,子架構之間必須頻繁的溝通。

DeepSeek混用上面三種模式,並加上一個新的模式:DualPipe。
DualPipe
這個模式運用兩個概念:
- zero bobble,亦即將閒置的時間縮短為0。執行的內容主要是把反向傳播中,對輸入(x)的梯度計算和對權重(w)的梯度計算分開處理,以及最佳化器(優化器,optimizer)的非同步[13]。有興趣的同好可以再去看論文,裡面還有很多技術細節。
- 雙流水線:雙向的流程平行處理。每一個GPU或處理單元至少負擔兩種模型子架構,且互為對稱;如此一來,當第一個micro-batch進到第一個單元時,第二或第三個micro-batch是從最後一個單元進來,雙向都做正向傳播。等到第一個micro-batch到達最後一個單元時,第二或第三個micro-batch也同時到第一個單元,彼此再同時反向傳播。這是一個複雜的設計,對於各子架構的設計有要求,權重的儲存也增加[14]。

在某些處理單元中,會需要同時處理正向和反向傳播。為此,他們重新安排處理順序:先處理MLP、再處理attention;先處理input的梯度,再處理權重的梯度。然後,與此同時,他們還負擔橫向溝通:利用專家混合架構,傳遞資訊(all-to-all)。這樣一來,幾乎是完全壓榨處理單元的資源,不讓他們有一絲一毫的浪費了。

結論:DualPipe的設計在於盡可能的避免處理單元閒置,並最大化的使用處理單元的資源。
FP8 資料格式訓練
在過往,深度學習訓練的資練儲存格式很常使用32位元浮點數(如Pytorch dtype = torch.float32)。近年來,一些實驗發現將資料儲存格式降為16或甚至8位元,並不會太過降低模型的表現。利用低位元格式資料的訓練方式被稱為「低精確度訓練」(low precision training)。之後也有提出混合資料格式的作法,即部分資料仍保有高位元格式,這類方法又被稱作混合精確度訓練(mixed precision training)。低精確度訓練可以有效降低訓練成本及時間,使騰出來的空間可以用來負荷更大架構的模型。然而,也可能造成一些極端的輸出、權重,或梯度,這與資料格式帶來的限制有關。
DeepSeek提出一種混合精確度訓練的方式:在輸入資料及部分梯度傳播使用FP8,在主要權重及梯度傳播的地方使用16甚至32位元,以避免極端值太常出現。不過資料格式的切換也很麻煩,尤其是要如何把低位元的資料轉換回去高位元而不失真,具挑戰性。
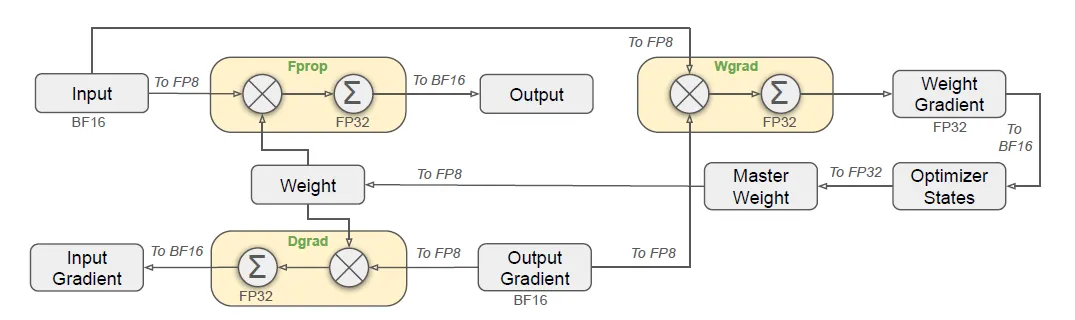
所以DeepSeek也提出兩個方法來解決問題:
- 較細緻的降低位元(fine-grained Quantization):這個主要是用在把資料格式降低位元數。傳統作法是把原始資料中的最大值對應到降低位元數的資料格式中的最大值,以此比例壓縮資料,但這樣一來,極端值容易出現。所以DeepSeek使用區段的方法,即把資料切分多區域,每一區域再去各自找對應,壓縮資料,可以降低極端值帶來的影響。
- 增加累積精細度:為了確保訓練品質,其實最好的做法是高位元數的資料格式。根據實驗,在NVIDIA H800 GPU上,FP8資料格式的累積精確度僅能到14位,遠低於32位元資料格式。因此,配合上述的細緻分割,在還原到高位元資料格式時,是採分區的方式,等到累積一定量的資料之後,再按照當初壓縮的比例逆推回去32位元。同時,利用H800的架構,一邊在做回推時,另一邊可以累積資料。這樣可以增加效率。
結論:FP8資料格式訓練可以提升訓練的效率,降低訓練成本,同時盡量保持模型的準確性。
強化學習:模型獎勵模式
DeepSeek使用一個規則式的獎勵模型,和一個模型式的獎勵模型。
- 規則式獎勵模型:對於可以用明確規則評判答案的問題,使用規則式模型來評估表現。這類問題通常有標準答案,例如數學問題、或程式問題。模型被要求按照固定格式產生答案,以便由規則式模型評估。
- 模型式獎勵模型:對於有標準答案,但沒有特定格式的問題,使用模型式獎勵模型去評估正確性。對於沒有標準答案的問題,獎勵式模型被設定去針對DeepSeek產出的答案和提問的問題做回饋。這個回饋過程包含思考鏈(chain of thought),以及偏好的答案等等。
強化學習相關的研究,主要在另一個模型DeepSeek R1上。
總結
DeepSeek集結了許多過往研究的成果,並嘗試基於這些成果改良。雖然不能說有根本上的原創性,但也不是完全沒有進步。單從Technical Report來看,的確不能說是抄襲。有一些技術的觀念都值德在進一步探討,細節非常多。
歡迎大家討論或思考。
[1] DeepSeek-V3 Technical Report,DeepSeek-AI
[2] Accelerating Language Models with Multi-Token Prediction,Himank Jain。https://medium.com/@himankvjain/accelerating-language-models-with-multi-token-prediction-9f0167232f5b
[3] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,DeepSeek-AI
[4] DeepSeek R1 vs V3: A Head-to-Head Comparison of Two AI Models,https://www.geeksforgeeks.org/deepseek-r1-vs-deepseek-v3/
[5] Attention Is All You Need,arXiv:1706.03762v7
[6] J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024.
[7] https://hackmd.io/@_E6GATP9Sz2h9WVqOqMDbg/SJgIu7xRp
[8] GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. arXiv:2006.16668v1
[9] https://www.mltalks.com/posts/176321695/
[10] https://medium.com/@himankvjain/accelerating-language-models-with-multi-token-prediction-9f0167232f5b
[11] Better & Faster Large Language Models via Multi-token Prediction. arXiv:2404.19737v1
[12] https://www.cs.cmu.edu/~15418/lectures/25-parallel_deep_learning_model_pipeline_parallel.pdf
[13] Zero Bubble Pipeline Parallelism. https://arxiv.org/abs/2401.10241
[14] Chimera: Efficiently Training Large-Scale Neural Networks with Bidirectional Pipelines. https://arxiv.org/abs/2107.06925