Nested Learning(NL):最完整論文解讀
讓模型真正模仿人類建立記憶
2025年9月附近,Google實驗室重棒出擊,繼8年前發表「Attention is All You Need」改寫自然語言及深度學習模型的發展路線之後,再次提出一個劃時代的想法。一樣如同過往,許多相關的討論文章如過江之鯽,迅速地充斥在網路空間。我也一如既往,選擇盡我所能地先消化論文之後,再整理成統合性高,比較容易閱讀,但能更深入論文的版本。
這篇文章會分成三個層次:
- 最簡單論述版:適合完全沒有任何相關背景的人理解,為什麼這篇論文這麼重要?他大致上做了蛇˙麼事情?
- 進一步延伸版:把公式推導的流程,轉化成文字敘述,讓有一定涉獵、或者主要是應用技術的人,可以更知道論文裡面的具體概念。
- 完整版:直接上公式,嘗試解釋各變數和公式的數學和物理意義,最後會上一張「公式整合路線圖」,歡迎想深入探討的朋友們,堅持看到最後!
廢話不多說,我們直接開始。最簡單論述版,就當作本篇文章的簡介吧!
簡單論述:論文的開創性
這篇論文,並不是原創性的提出嶄新的公式、演算法、或模型。相反的,他們決定反璞歸真--採用部分以往機器學習的概念,搭配神經生理的知識,重新解釋現有的深度學習模型。其實,看完這句話,就足以出去當做談資了。若有耐心,就再看看下面的內容吧。
人工智慧的歷史
人工智慧從二次世界大戰結束以來,經過80多年的發展,經歷了三個主要發展期,和兩個冰河期。

第一次AI發展期,主要是電腦被發明,大型運算開始能交給機器處理。此時人們便開始考慮「機器智慧」的可能性,並想像過將機器設計成能夠像人類一樣思考。在這個階段,配合神經生理學的發展,人類想像的是模仿人類腦部構造,建立人造神經元,利用人類的邏輯數位化,以達到人工智慧。著名的圖靈也是這個時代的人物。
發展了大約20-30年後,由於計算機硬體設備發展開始陷入瓶頸,加上模擬人類思考運算需要的計算量過於龐大,遠非當時硬體能負擔,因此進入第一次的AI低谷。
第二次的AI發展期,著重在人類規則的建立。也就是說,務實一點,不再要求機器完全真正像人一樣思考,而是模擬部分規則。這些規則,有些是基於邏輯,有些則基於專業知識。研發出來的結果,就是演算法和專家系統。這些概念某方面改進了系統自動化,而且影響也持續到現在,很多系統或資訊處理的方式都奠基於這個年代。
然而,一樣是因為經費和硬體發展的瓶頸,導致第二次的AI低谷。此外,人們也發現,這些演算法和專家系統,僅能處理一部分範圍的狀況。雖然在開發時,就已經預期它不能處理全部的狀況,但實際上能應對的卻比預期的還要少。此外,專家系統牽涉到領域知識,而這就讓一些規則並不是這麼好擬定,系統很容易在常常更新的知識系統出錯。這就進一步壓縮了這些人工智慧的成效,連帶降低使用的意願。
第三次的AI發展,延續至今,主力在於神經網路。這是一個厚積厚發的過程,關鍵的切點就在硬體的開發設計,終於跟上了理論。前15年(90年代-10年代初期),受限於硬體,理論開展不少,但很難落地,即便實作了,成果也不如機器學習演算法。但GPU的平行運算,讓神經網路的計算量、速度,都獲得突破性的改變,一旦深度學習網路在特定領域,超越了傳統機器學習,這個優劣之勢便從此逆轉,再不回頭。如今,深度學習在電腦視覺的辨識、分類、偵測,自然語言的語意分析、文意整理,甚至是文本生成,都遠非傳統機器學習方法可比擬。當然,這不是說機器學習方法已再無用武之地,反過來說,對於一些資料型態,機器學習方法仍然有其優勢。一如機器學習方法也不會取代傳統統計,變成生醫研究上唯一的檢定分析方式。
當前模型的限制
Google在2017年提出Transformer,關鍵概念是「自注意力」(self-attention),可以簡化理解為,在一個文字段落中,模型同時評估對於每個字,同段落或語句中的其他字的重要或關聯性。這件事對於文意理解,乃至於文本生成都很關鍵,而事實也證明,發展至今的自然語言模型、大語言模型,都基於此。但除了這個關鍵概念,其他的計算方式、單一計算模塊的設計,乃至於模型堆疊計算模塊的方式、最佳化方式等等,都在一路以來發展的深度學習架構下面。
而如今,這篇論文提出的第一個質疑就是
「深度模型使用神經元網路運算,但真的有讓整個神經網路模仿人類的方式運作嗎?」
這是一記對於深度學習模型概念的靈魂拷問。但Google實驗室提出這個質疑,並不是為了問而問,也不是為了標新立異,嘩眾取寵。他提出的理由有三:
- 當前深度學習的模塊堆疊方式,並沒有真正構成類似人類腦部神經元的學習模式。藉助GPU的平行運算,模型的確能同時計算或學習廣泛的區域,這點甚至可能已經超越人類。但在學習的深度上,仍然不如人類。
- 模型本身的記憶深度很淺。模型並沒有建立一個迭代的記憶模式,而是在訓練過程中利用權重,記錄損失造成的差異,然後就結束了。它不像人類記憶,有短期、中期、長期。
- 模型在訓練完成之後,便不再學習。我們所有的模型運用,讓模型曝露在新的知識或資訊區域,但模型仍然是拿之前訓練學習、記錄在權重的那一套出來應付,而並沒有因此真正把這些新的資訊或知識儲存在架構裡面。即使有提示(prompt)甚至內文工程(context engineering),模型也只不過是把它儲存在外面的文字檔案,而非真正內化在模型本身。
這篇論文也試著針對這個提問,提出自己的看法,並非問而不答。

人類的記憶分成短期、中期和長期記憶,其中關鍵在於短期記憶,和短期記憶轉成中長期記憶兩個步驟。一般人類接觸到的外在資訊,都會先儲存在短期記憶區。大部分的短期記憶,在即時處理完之後,就不再保留。人類需要透過一些行為,將短期記憶轉變成長期記憶,例如覆誦,或睡眠時大腦的記憶重整。從這裡就可以看出,短期記憶和長期記憶性質上的區別。短期記憶快速更新,而且不會長期儲存。長期記憶需要透過比較深刻的學習行為,由大腦重組,更新較慢且不易被覆寫,具有持續和一致性。
對照到當前的深度學習模型,和人類記憶的最大差別,便是在長期記憶,以及持續學習這兩項。所以,論文提出針對這兩個方向的構想,目標是讓模型能更貼近人類學習和建立記憶的方式,以讓人工智慧能更往前一步。
切換視角
論文首先把現有的深度學習模型單元(感知器,MLP),用另一個角度思考。原本利用權重更新,將模型貼合資料分布形式的過程,被轉變為記錄「每個輸入,和輸出-正確答案之間差異」的字典。利用這個概念,模型開始有記憶。在整個訓練過程結束之後,這些權重被更新,而記憶的最佳點也都被記錄下來。訓練過程漫長,而相對不容易被覆蓋,類似模型的「長期記憶」。
與之相對的,是計算注意力的模塊,或是調整學習速率/動量的最佳化模組,在訓練過程中,他們的調幅很大,只要小小的變化,就可以大幅度影響模型輸出,但也更新快,在訓練之後他們不會被保留,這些特性就比較像「短期記憶」。
論文提出的視角轉換,把每一個過往套疊在深度學習上,分屬不同功能的模組,轉化為更新幅度不一,但各自擁有功能的記憶體。模型瞬間人性化許多!
不只如此,論文也提到,模型也可以在使用過程(inference)建立記憶。這個記憶的生命週期雖然只在單次任務裡面,但能讓模型更好的應付長文字段落(long-context)和持續學習,在這兩方面的表現比傳統注意力模型要更好。這是一個突破:模型第一次在使用時,仍能建立記憶。
如果看到這邊還意猶未盡,想要更進一步探索比較具體的內容,就往下看吧。接下來是深入一點的延伸版本。
重新思考模型,定義流程
論文裡面首先定義「記憶」是什麼。記憶是一個矩陣,儲存索引和內容。利用索引和內容乘積所展開的矩陣,加上一個觀測函數(objective function,通常是損失函數loss擔任),就可以進行訓練和最佳化。
例如,一個感知器,他的權重就可以被設計成矩陣。以往的梯度,評估的是模型輸出()和標註()之間的差異。轉化成記憶,對照的是把輸入(x)作為索引,梯度被視為一個落差(論文給予一個專有名詞local surprise sign,LSS)而當作內容。最終,要把這個記憶最佳化,當提出x輸入模型的時候,模型要能藉由LSS,把輸出和最終答案的落差降到最低。
延伸
再看看attention的例子。原本的attention計算,其實是直接把QKV依序相乘,並沒有任何權重在公式裡面。可訓練的權重,只在分別將Q、K、V投影到向量空間的投影向量上。論文中,把attention模組視為一個記憶模組,索引和內容就對應到K和V。如此一來,連K和V之間的關係,也可以透過記憶的方式更新,算是原版attention的改良版。
需要注意的是,attention記憶模組和MLP記憶模組是不一樣的。如前所述,attention在每個token之間迅速的重新計算,所以記憶的更新速度,是以token為單位,而且變化很大。相反的,MLP的權重參數,由於梯度反向傳播,加上使用學習速率限制步長,更動的幅度非常小,必須累積到以epoch,甚至是整個訓練過程完成的時候,才能看出明顯的差異。所以,當傳統模型將attention模組和MLP疊合,就天然形成了兩種記憶模式:短期(attention)和長期(MLP)。
多層記憶,不同時間尺度
我們來看看傳統深度學習中,「動量」(momentum)在NL中的角色吧。動量的設計目的是讓權重在更新時能更滑順:如果有持續向某個方向更新的趨勢,動量會讓下降速度增快。如果方向不同,則可能會降低更新速度。更新的方向,自然取決於梯度。
接著就有一點技術性(tricky)了。NL把動量迭代權重中,持續接收梯度的過程,視為一種記憶。利用這個概念,NL把動量轉化成一個類似權重更新的公式,但目標是最小化梯度和動量關係。配合權重更新的概念(xLSS),動量在NL就有兩個層次的解釋方式:
- 序列性的記憶最近的梯度:這是貼近動量的原始定義。在這個定義下,記憶沒有索引,單純依照距離當前位置的時序性儲存。
- 屬於資料分布映射LSS的關聯記憶:這是經過權重更新的概念,代換公式之後得到的結論。簡單來說,就是權重更新是第一層記憶,而動量則是依據權重更新,控制的第二層記憶。在這個情境,記憶也有索引,也就是x⇒LSS。
到此,動量也被整合在記憶系統中。這種多層次的記憶,呼應人類神經生理的機制,長短時間尺度不同,也就是NL名稱的由來。
Optimizer也可以併入記憶系統
動量可以看成一種統合式學習(meta learning):將梯度映射到屬於動量的參數。承接這個概念,NL繼續把優化器(optimizer)變成記憶系統的一部分。在這裡,論文針對映射使用的向量乘積(dot product)提出改善方案:使用 regression及delta rule,使動量記憶能保存得更有品質。尤其,因為動量儲存梯度的精神,本質上是單層線性的,這讓 regression及delta rule已經足夠,是個相當適合的低成本方式。把它代回最初的權重更新表示方式,可以得到一套新的梯度下降方式,來自於傳統深度學習梯度下降法,加上一些變異。
整體來說,論文從改寫權重更新的方式開始,介紹NL的核心觀念。等到讀者比較適應這種表示方法之後,就開始改造動量和優化器,並將其加回原本的權重更新方式,得到一個變異型。所以,從數學式上來說,論文並不是只有換個角度看原本的深度學習模型,它是有改造的。
只是,從物理意義來看,這個改造不是太大,基本上還是圍繞在原本的深度學習定義上,讓它看起來像是只換了個視角而已。也因此,過度輕視這個環節,可能會誤解論文的本意。
如果看到這邊還是意猶未盡,那我們再進一步,把論文中的數學式理一理。這段難是難在整個邏輯順序的確立,以及如何切換視角,倒不是難在數學式本身。
數學式解析:讓公式說話
先上一個公式指引圖。
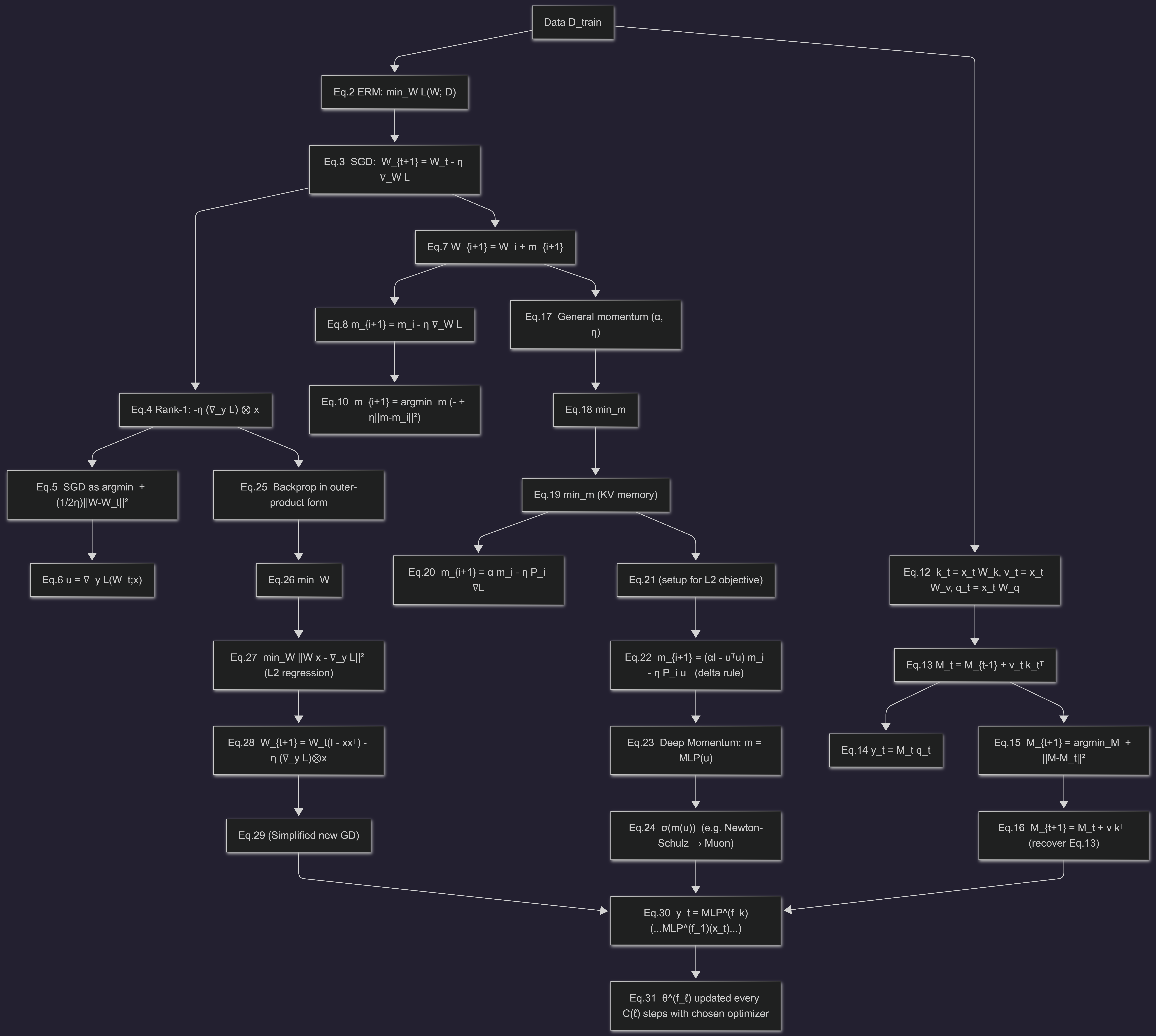
因為繪圖的mermaid不支援latex,所以圖內的公式看起來並不自然。不過,仍然可以用數字去對照論文內的公式。以下按照流程圖依序說明。
1. 原型:權重更新和隨機梯度下降
這個是全部的開始。關聯記憶的基礎定義:記憶矩陣將所有的索引映射到值。為了學習關聯記憶,使用一個損失函數(objective function)來評估記憶矩陣的品質,目標是將它最小化。
利用這個公式,我們可以把權重更新看成是模型將權重和資料之間的映射,而損失就是梯度。
而最佳化的權重,依梯度更新的表達式則為
為的輸出。,若定義,則式(4)可將傳統模型梯度下降的權重更新,視為u和x之間的映射關係。對照式(1)、(2),若把當作記憶矩陣,則可寫為
其中是正則項,而則是一階泰勒展開式近似的結果。根據式(6),可以把模型權重更新,梯度下降解讀為一個把資料點映射到的關聯記憶,u位在特徵空間(representation space),這邊論文給它一個名詞,也就是上面提過的LSS。LSS本質上是紀錄輸出y和loss之間的差異,向量性的差異。
需要注意的是,這個流程僅止於模型訓練階段,也就是說,記憶形塑在訓練過程結束之後就終止,不會再有新的記憶出現。測試或應用的時候,不會有記憶型塑,這也和傳統的模型訓練概念吻合。
2. 把動量概念轉成關聯記憶的一種
基於上面的公式,現在把動量的概念導入。結合動量的權重更新式為
其實就是先用動量處理「梯度乘上學習速率」這部分,再讓權重基於動量更新。既然如此,我們可以根據式(4)到式(5)的轉換方式,處理式(8),得到
這邊公式編號對照論文,為求一致,沒有寫出的公式會跳過編號。式(9)和式(7)一樣。式(11)改寫來自式(10),如同式(6)改寫自式(5)。值得注意的是,這裡的損失函數和式(5)(6)的損失函數,雖然都寫作,但並非同一個。可以觀察到,這裡裡面的內容也和式(5)(6)不太一樣,因為這邊是針對動量,而式(5)(6)則是針對權重。式(6)的目的是引出LSS的概念,那在這裡,式(11)的意義是什麼呢?
式(10)來自於「傳統模型對於動量的定義」,即「時序性的紀錄最近的梯度和趨勢」。動量本來就和梯度反向,因此給予負號在前。在梯度多次驅向同一方向時,動量可以加速收斂;若梯度開始出現發散方向,動量也可以適當的減速,讓模型訓練過程更順利。式(11)將u代入改寫,使動量也變成一種記憶系統,紀錄的是輸入x和LSS的關係。因此論文說動量的計算式可以看成兩種意義:無索引的時序性紀錄梯度,和有索引的x和LSS映射。
同時,加入動量之後,模型變成兩層記憶:動量的x對LSS映射,和權重的x對LSS映射。兩者平行,而且更新時序不同。動量的變化,對模型即時(訓練時)的輸出變化,影響較大。相反的,權重在訓練過程中的變化,對於模型的輸出影響很少,必須要等到訓練完成之後,權重變更累積出來的效應才比較明顯。因此,動量是相對快速更新的記憶(fast weight),而權重則是慢(slow weight)的。按照公式,動量是內層(inner,先算)的(式(10)(11)),權重則是外層(outer,後算)(式(7))。
3. 線性注意力模塊(attention block)
上面提到的權重更新,是基於多層感知器(MLP)的基本算式。接著,論文帶我們來看注意力模塊怎麼變成記憶系統。我們有一個資料集,以及一個單層的線性注意力模塊,在任務上面追求最低的損失,使用梯度下降。在未標準化的線性注意力,公式如下:
這邊要注意的是這行。原本的注意力模塊計算式裡,沒有記憶模塊(只有)。所以這邊已經有點改變原本的架構了。這個記憶模塊的目標是映射key到value。對標式(3),若把當作梯度(),結合式(1),在學習速率的情況下,可以得到
意思是說,記憶是可以連鎖(recurrence)的。這邊幫論文稍微引申一下:為什麼要推導這一段的式子?因為這個連鎖性。它有三個特色,是以往深度學習模型不具備的:
- 記憶的更新,發生在模型運算時(forward),而非反向傳播時。這除了讓模型有模擬學習記憶的行為之外,更重要的是,實用(inference)時只有運算階段,沒有反向傳播。這讓模型在實用時還能繼續學習。
- 記憶可以連鎖,表示模型反覆迭代,而且記憶是基於之前的記憶來調整的。這點乍看之下和以往深度學習模型權重更新非常類似。但差異在下一點:
- 它整合學習規則在裡面。這個規則,不是單純的權重下降,而是還包括如何調整權重。因為多尺度的記憶系統,可以把動量、學習速率、甚至優化器都整合在一起,橫跨訓練和實用階段,讓模型有機會掌握更本質的學習原理,而非僅在訓練階段,將上述的項目作為外掛,調整超參數使用。而且因為它是真正干涉到權重更新,和以往RNN/LSTM只是更新hidden state的概念也不一樣,記憶具有對模型更高的價值。
回到注意力模塊。式(14)和式(16)說明注意力模塊也是一個雙層的記憶系統:外層記憶系統是以前的注意力權重更新(主要是QKV的投影向量),內層記憶則是我們的kv映射記憶。和動量一樣,內層記憶更新得快,而外層記憶更新得慢。
4. 優化器作為記憶系統
進到優化器前,我們要先回來看動量:
可以參照式(8),兩個式子基本上一樣。這邊是把優化器中,動量相關的參數也引入,在優化器中,動量有可能隨時間改變(decay)。為求簡化,在的情況,可以得到
這其實是式(10)的變化版本,把和合在一起,內積的另一側就變成單位矩陣。但無論哪個式子,都是說明動量的計算過程,可以看成將梯度記憶在參數裡。式(18)把式子寫成式(1)的格式,以符合原型定義。但單位矩陣沒有數值,這讓記憶系統稍微不夠力。論文在這邊決定把單位矩陣換成一個參數矩陣,因此變成
而把式(17)改成
接下來會從這裡做三個方向的延伸。
延伸1:改良損失函數()
到目前為止,我們在都是用內積(dot product),這個方式對於對齊兩個向量的方向有幫助,但論文認為不夠強力。因此,他們選用 regression來代替內積,也就是。於是式(20)可以改寫為
這是把 regerssion微分之後的結果代回式(20)的再重新整理的結果。利用delta rule,記憶的更新會比較穩定。
延伸2:改良記憶模組
到目前為止,記憶模組本質上是一個數值矩陣。論文提出,可以把模組替換成更強力的函數,例如換成一個MLP。於是式(17)可以改成
其中,而意思是第二層的損失函數,只針對動量()和第一層的梯度()而和無關。論文中沒有限制這第二層的損失函數應該使用什麼,也可以再使用內積,但這邊就真正建立了第二層記憶自屬的損失函數,而不再是由第一層損失函數直接計算出來。換言之,第一層(外層)記憶的梯度,成為第二層(內層)記憶損失函數的輸入。梯度之中還有梯度,因此論文將它命名為「深層動量梯度下降」(Deep Momentum Gradient Descend,DMGD)。
延伸3:非線性輸出
延續上面,既然都用MLP來當作動量的記憶模組了,那模仿神經網路,再加上一個非線性的函數(即神經元的啟動函數)也很自然吧?因此,把式(23)改成
其中就是隨意非線性函數。
不只是單純的反向傳播
現在把鏡頭拉回式(3)(4)。反向傳播中,梯度下降的一步,可以寫成:
其實就是式(6)扣除正歸項。但這樣的作法可能會忽視之間的相依性。為了把相依性也考慮進來,論文要把損失函數換成 regression:
並把其微分結果代回式(4),出現類似式(22)的結果:
這將是我們接下來最後一個段落,HOPE的優化器核心。
5. HOPE:自參考學習模組及持續的記憶
要把上面幾個區塊整合起來了。
首先,從NL的角度,論文已經說明它主要由兩個部分組成:一、快速記憶:工作/訓練當下更新,例如注意力模塊,在一次的forward裡面,隨著token進入,就會一直計算修正;二、慢性記憶:經過整個訓練流程之後,才比較穩固,例如權重,必須經過很多次的反向傳播,才能有明顯的變化。這樣的分類,呼應人類生經生理的記憶型塑。
權重這類的慢性記憶,更新慢,實際上也不應該常常更新。它的記憶是相對比較長期的,在以往的模型裡,就是模型的骨架,訓練結束也會一直存在。動量或注意力模塊裡的記憶,在以往的模型中,則只存在於訓練階段,不存在於實用階段。這符合人類神經生理的概念:長期記憶不太更新,以免造成記憶結構破壞。人類的長短期記憶,在過往已經有模型模仿過,就是自然語言模型的濫觴之一:LSTM。只是,當時的長短期記憶,針對的是文字段落(上下文)裡面的長短,而非NL裡面的記憶更新,兩者記憶的指涉對象不同。因此,LSTM是把計算結果暫時儲存在隱藏層,裡面並沒有NL記憶的成分。
所以,接著基於長短期記憶的原理,論文提出一個連續型記憶(Continum Memory System,CMS)系統,指的是把以往模型裡,有明顯分野的兩種記憶型態,藉由多層次的記憶系統彌補中間的空檔,讓它的記憶長短性不要落差太明顯。如同式(23),這些記憶系統各自負責當前部分的損失,但輸入是使用前一層記憶的梯度。若模型使用MLP堆疊,每一個MLP的記憶更新時間長度為,對於輸入的輸出為
在第個MLP的參數,間隔每的時間更新記憶:
表示除以 的餘數為0,也就是說,在第個MLP,記憶只在達到的時間間隔及其倍數時才更新記憶。是任意梯度下降的函數,或優化器。相較於NL,注意力模塊就是只有一層「真正定義上」的記憶了:權重更新,事實上,跟傳統的MLP是一樣深度的。
這其實引伸出思考的深度和廣度:注意力模塊擅長平行處理,而且能用以乘載廣泛的上下文,但這是廣度,而非深度。在隨著堆疊的注意力模塊往下的過程中,事實上都在處理同一個token,而非像NL一樣,有不同層級的模組,更新不同層級的記憶。所以NL是在注意力模塊的基礎上,加上了不同層級和頻率的記憶更新模組,希望以此真正加深思考深度,而往更貼近人類大腦運作的邏輯一步。
NL真的完全仿照人類的記憶模式了嗎?
當然沒有。
至少有一點是人類有而NL沒有的,就是無論NL如何堆疊記憶模組,它也暫時沒有辦法仿照人類建立一致而真正穩定的長期記憶。人類的長期記憶可以橫跨很長的時間,且不易被修改。目前所有的模型,包括NL在內,並沒有這種「活化」的長期記憶。所謂活化,指的是可以討論,可以修正(雖然不容易),且修正後仍可長期持有的記憶。所有大語言模型,依據資料訓練儲存在權重裡的知識,仍然容易被修正,容易不一致(產生幻覺),頂多只能算長期持有的死記憶。
究竟需不需要訓練一個模型去做到類似人類的長期記憶?這是屬於哲學的問題,不完全是技術問題。隨著NL的記憶模組堆疊,是完全可以做出真正長時間才更新的記憶。當然,這個過程目前還卡在訓練和實用是完全分開的階段的問題,也就是說,隨著訓練結束,這些記憶模組中的參數並沒有保留。他們保留的,比較像是學習的方式,這一點其實有點類似過往在few shot裡面提到的meta learning(元學習,個人偏好翻成統合學習)。實用時,會重新依據輸入的資料,更新記憶模組以輔助輸出結果。
總之,本篇文章把NL的理論內容,依照三種不同深淺層次的方式介紹。希望看到這邊的各位,確實能有不一樣的收穫。如果有收穫,麻煩幫我分享,也可以註冊會員收藏本篇文章。
資料來源
[1] Nested Learning: The Illusion of Deep Learning Architectures. Ali Behrouz, Meisam Razaviyayn, Peiling Zhong and Vahab Mirrokni. Google Research, NeurIPS 2025.