大語言模型的行為與迷思:他的行為能信任嗎?(2)
意料之外,卻又預期之中的結果
我們在前篇討論到大語言模型的行為和信念,並由此延伸出一篇研究,圍繞在試著找出模型本身是否能在行為邏輯上,符合自己的判斷--如果他真的有「信念」的話--並依據判斷採取行動。
那這篇我們來看具體實驗設計,以及結果吧。
實驗設計
作者選取的實驗材料竟然是醫學相關的,這讓我蠻意外的。有四個醫學診斷相關的任務:其中兩個使用真實世界資料集(real world data),而另外兩個使用貝氏專家網路,是跟小兒科有關的資料集。作者使用四種大語言模型來測試,分別是:
- GPT-5 高推理版(high reasoning)
- GPT-5 基本推理版(minimal reasoning)
- DeepSeek R1 671B。這是一種偏向專家領域和強化學習訓練的模型,可參考這篇有比較詳細的資訊。
- Llama-4 Scout 17B
統計採用bootstrapping(隨機採樣但放回),報告95%信賴區間,5個隨機種子。每個資料集採200筆,抽樣5次,總共1000筆。
真實世界資料集:兩種
第一種是心臟病資料集。有心電圖和流行病學相關資料,標註是否有結構性心臟病。第二種則是糖尿病,資料包括病人記錄,例如運動習慣、血糖值等欄位,標註是否有糖尿病。
真實機率(,或,這邊作者略寫)的計算方式為:把所有落在相同共變數組合(covariate strata)的病人找出來,計算其中確診為陽性的比例。而且每個組合至少要有 100 個病人,才會被納入計算,避免樣本太少導致估計不穩定。這個作為實驗的標準答案,也就是ground truth/label。
貝氏專家網路資料集:兩種
可以把他想像成一個診斷工具,給定臨床症狀之後,網路會回饋是否有符合某個診斷。這些計算是基於流行病學所建立,所以某些症狀會被作為網路中的節點,有與沒有則會改變最後判斷的機率。兩種都是兒科相關,第一種網路資料是發燒,包含人口統計與症狀(例如黃疸、嗜睡)。第二種網路是哭鬧,包含觀察到的症狀(餵食困難、腹部膨脹)和潛在病因如腸絞痛或脹氣等。
因此這邊是拿貝氏專家網路計算的機率當作ground truth/label。模型會被提供和專家網路一樣的資訊,讓其判斷可能性,再和計算結果對照。由於貝氏網路計算出機率的過程,所經過的節點都是透明的,可重複而且可掌握,因此可用於計量模型的行為和推估的機率等等。
任務
四種資料集都被設定成「有/無」的診斷,加上「拒絕回答」,模型總共有三種答案可以選擇。模型會先被問能不能回答,如果不能回答,就將模型的答案定為「拒絕回答」。若可以回答,則進一步要他選擇一個答案。這樣的好處是,模型不會一開始就被兩極的答案中強迫要選一個回答,而也不會讓拒絕回答選項,變成干擾模型選擇答案的因素,讓實驗設計上客觀一點。
提問(prompting)
首先,信念和採取怎樣的行動,會在分別的窗口(context window)提問,以避免互相干擾。預設的提示詞是不使用任何附加條件的,例如告訴模型依據什麼評分方式,或者暗示使用貝氏定理來計算條件機率。除此之外,不特別探究提示詞的寫法,例如context enginering,或其他任何相關的方法,目的是確保實驗場合的通用性。
介紹完實驗材料和設計,來看最期待的結果吧。
結果
評估一、條件獨立測試
複習一下定義:模型一旦依據信念產生,便無法再從得到任何資訊,也就是說,知道不會改變採取行動。這也是這個評估的虛無假設。圖一是測試結果:
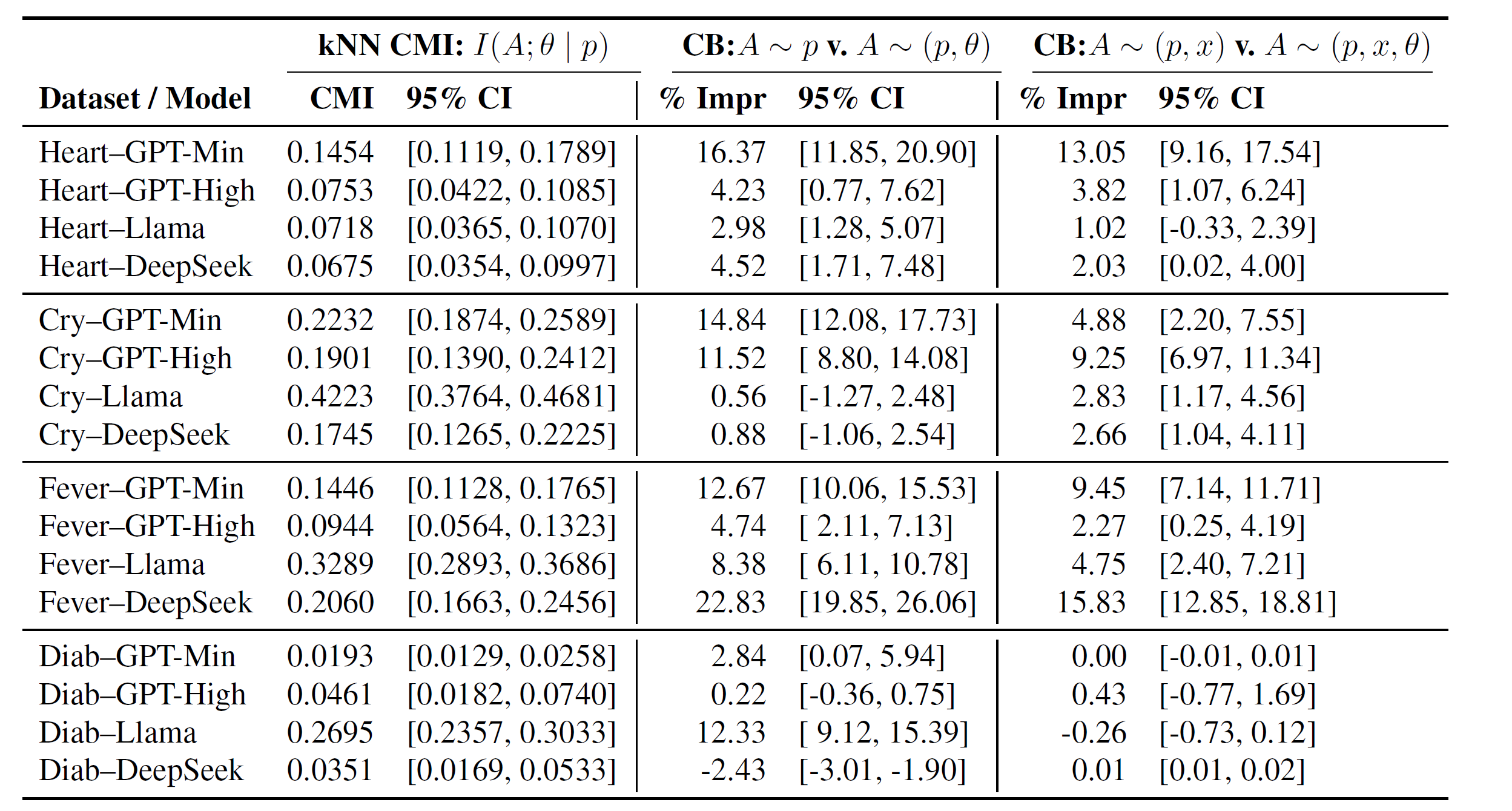
這個表格解釋起來有點費功夫,先從最左欄開始吧。左上看到kNN CMI,我第一時間也是困惑的,因為在實驗設計裡面沒有提到會用kNN。不過,不必擔心,這邊用kNN的目的不是要做非監督式學習,也沒有要用它來預測任何目標,純粹是利用它來把資料點分群。由於機率是連續變數,我們如果執著在固定的數字上(例如p=0.7),去找對應的資料來作分析,那量可能會少到沒有辦法統計。所以kNN在這邊是協助把一定附近區間機率的資料整合起來,盤點他們的和,來評估是否具備獨立性。
我們舉具體一點的例子好了:假設在p=0.7附近區間抓到一群資料,其結果如下:
機率在0.7附近,模型一律採取行動為Y,不因為的差別而有改變。表示機率和模型採取的行動高度一致,這表示給模型的已足夠他形成信念並支持他的行動。你可能會問:但實驗的時候我們也沒告訴模型呀!沒錯。但如果資料長下面這樣:
看出差別了嗎?我們只給,但模型在為0的情況下,即使機率在附近區間,竟然採取和一樣的,這表示模型可能還藏了些什麼會影響他採取行動的資訊,而沒有完全展露在判斷機率的時候。這就是所謂的「改變」,也就是有訊息差,條件不獨立。
所以基本上,CMI必須為0,或接近0才是證明模型有做到獨立性。不過這邊作者選用的k只有3,意思是分三群,我推測,可能跟選擇也只有三個方面有關係。不過這樣一來,誤差有可能偏高。整體來說,所有實驗都推翻虛無假設,即條件獨立全部不通過。作者可能也擔心誤差,因此在這欄,CMI僅當作定性分析,並沒有直接用他的值來測量資訊差的大小。
定量的實驗,作者交給CatBoost。具體作法是把我們上面的表格直接拿去訓練CatBoost,讓他判斷。這邊分兩類實驗:第一類比較單純,就是用訓練兩組CatBoost,一組用預測,另一組用和預測,然後比較兩組的logloss,利用bootstrap的方式反覆抽樣建構logloss的分布,看看95%的信賴區間在哪裡,可以進一步知道訊息差到底多大。
中間欄就是呈現這個實驗結果,而只有cry-Llama/cry-DeepSeek/diabetes-GPT-high的誤差值跨過0,表示信息差不明顯。GPT-min普遍表現都很差。
同時,為了確保的貢獻實際上來自,作者另外做第二類實驗:也就是在第一類的基礎上,兩組模型都額外加上訓練,再來比較。結果看起來,四組模型在糖尿病資料集的表現上都還不錯,反而是剛剛第一類實驗中表現還可以的cry-Llama/cry-DeepSeek變成都在正值,資訊差反而更明顯了。
但要注意的是,這和模型對問題回答的正確度本身無關,這篇研究也不在乎這個。作者在意的是,比起出錯,模型更「言行合一」,錯,也要錯個徹底。
評估二、單調遞增機率
這邊是顯示各模型對上各資料集的時候,採取的選擇和機率的變化有沒有符合一致性。例如,隨著機率增加,選Y的比例增加。圖二是把「達到顯著統計意義」違反的比例做成表格。
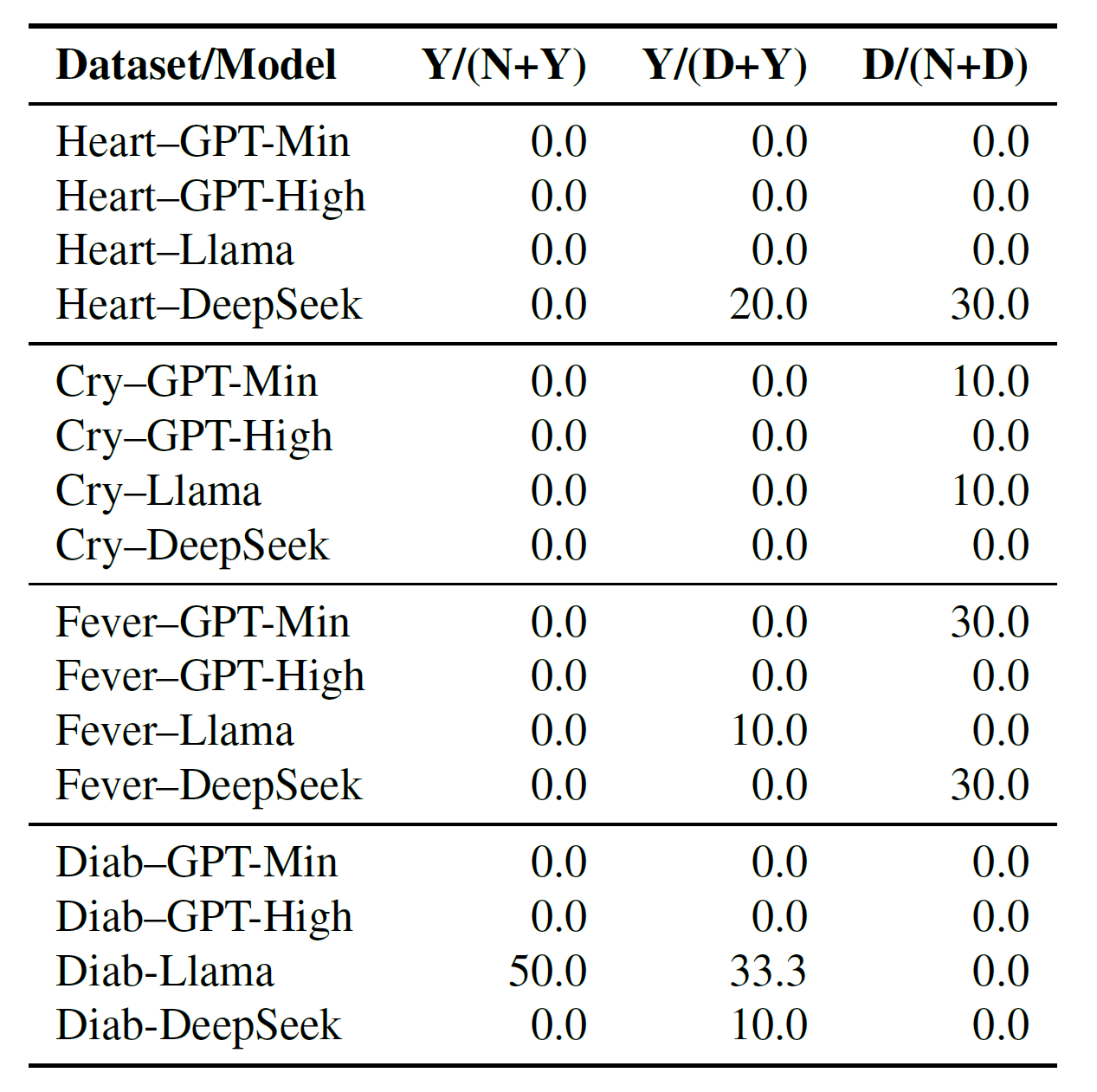
和第一個評估遇到的問題一樣,因為機率是連續性的,實驗的作法是把它切分成好幾個區域,然後比較個區域間採取某一行動,佔該區域資料點的比值。理論上,單調遞增的情況下,較高機率區間採取該行動的比值,應該要一致的比較低機率區間高或低,取決於採取的行動是哪一種。在實驗中,有三種行動可採取,因此比較時,會把其中一個行動剔除,只比剩下兩個行動。
假使模型在採取Y行動上是單調遞增好了。那如果有任兩區間,出現較低機率區間,採取Y行動的比例比較高機率區間還多的狀況,那就是違反單調遞增。只有這樣,我們還不能確定這個違反是否有統計上的意義,所以還必須進一步分析,按照分布,出現這樣的機率是多少?舉個實際的例子:
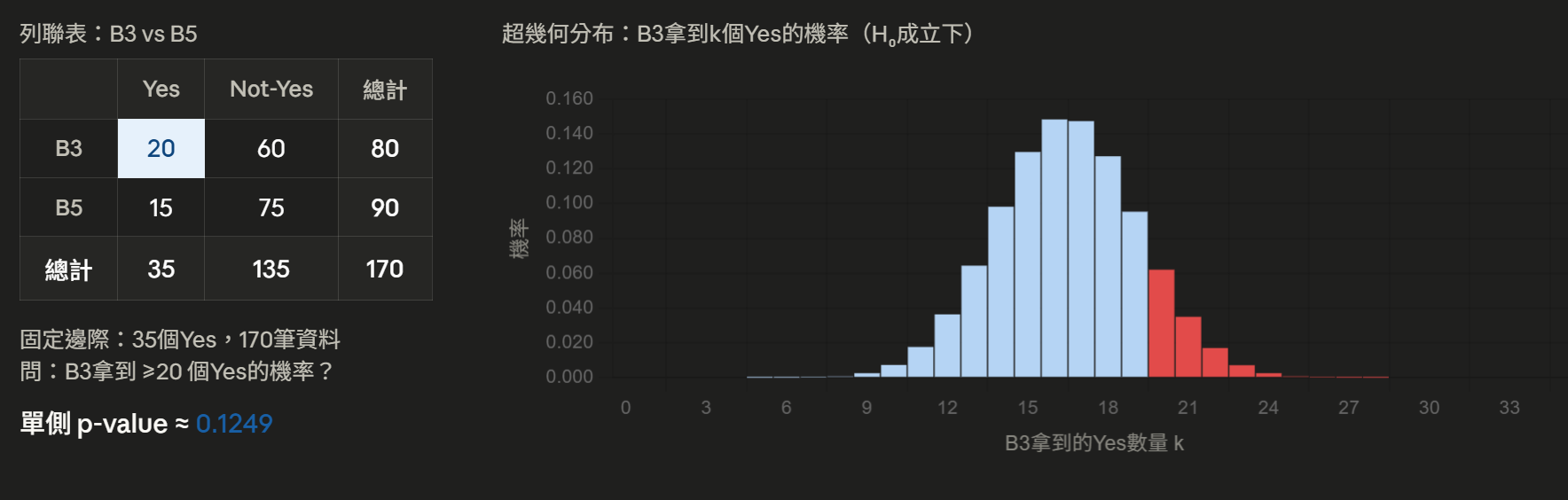
如果B3機率區間<B5機率區間,但在B3卻有20/80=0.25的比例採取行動Y,而B5只有15/90=0.167的比例,是違反單調遞增的。這時Fisher's exact test的作法是:把兩組資料全部混在一起,重新分配,會得到B3和B5各自拿到不同採取Y行動的資料點數目。依據這些不同數目出現的機會,形成一個機率分布,我們就可以調查:在觀察到B3拿到大於或等於20個的機率是多少?也就是圖三中,紅色的區域。在模擬數據中,這個機率是0.1249,表示說即使B3和B5兩區間的資料分布一樣,也有12.5%的機會B3拿到20個,而B5拿到15個。實驗中認定推翻虛無假設的要求是<5%,也就是機率要低於5%才會被認為是極端狀況,有統計顯著意義,推翻虛無假設。因此在這裡,模擬數據是無法推翻的,意思是說還在兩者資料分布一樣的時候,可能出現的合理狀況內。
回到實驗的數據。統計出有顯著差異之後,這樣的一組比較就會被登記下來,然後再尋找其他任兩個機率區間的資料作比較,如果有違反單調遞增則再做檢定確認,如此反覆,直到所有區間都被匹配比較完成。這當中,當然相鄰的區間出現違反的機率,會高於相距較遠的兩個區間,但大體上每一個模型-資料集實驗被分成的區間,不會相差太多。除非一種狀況:資料都大幅集中在某一機率區間,此時考慮到如果還是把100%的整段機率區間等比例切割,可能出現某些區間資料數少到無法配合檢定的情形,就會被迫切割成許多小而相近的機率區間,那出現違反單調遞增的風險就增加了。
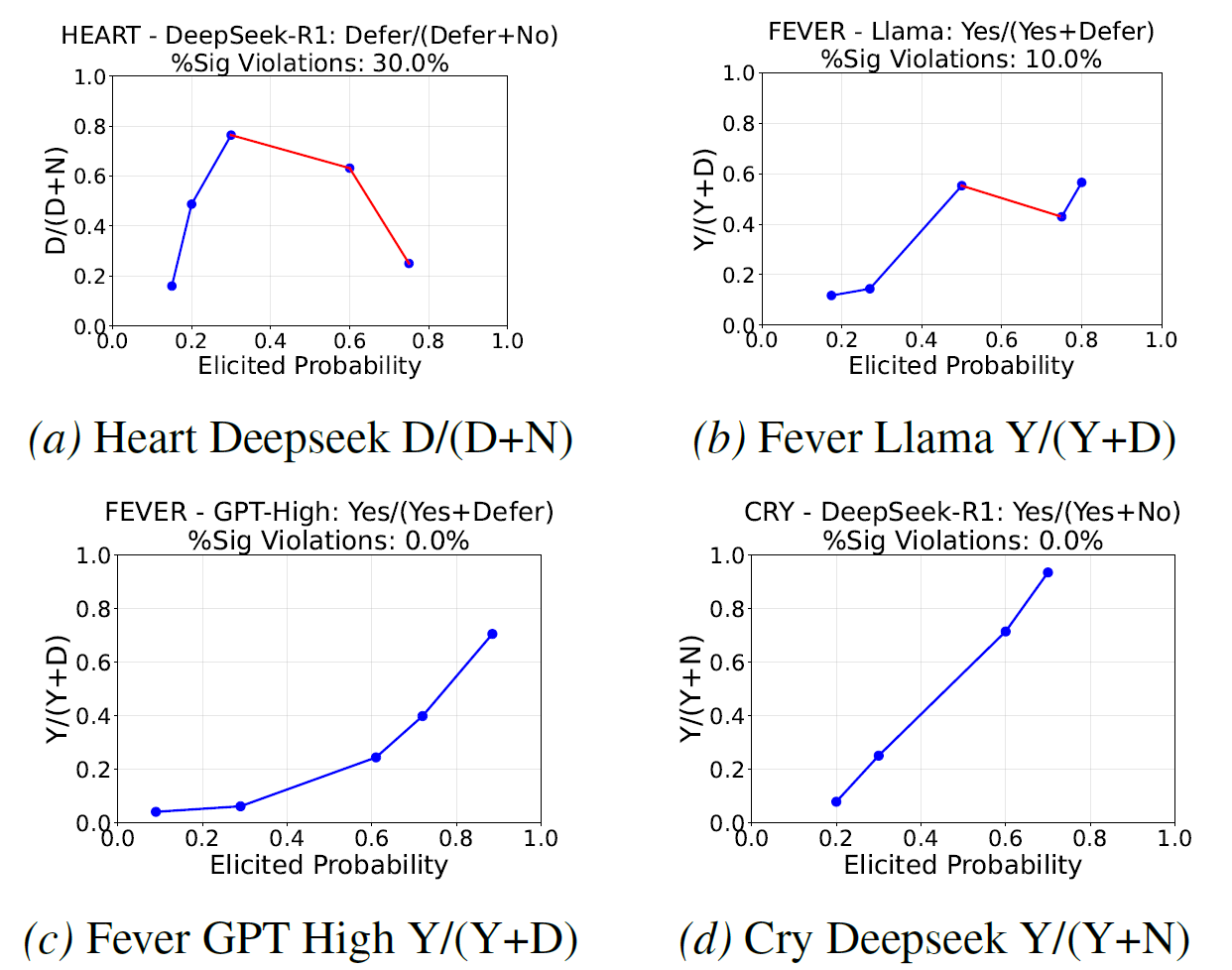
圖二顯示出GPT系列的模型較不會違反單調遞增,而再評估一表現還不錯的Llama和DeepSeek,則出現了幾個違反的狀況。而下圖則更具體的顯示了單一模型-資料集是否出現顯著意義的違反時,其比例的變化。
評估三、跨任務一致性
評估模型不會因為更換提問的方式,就改變對題目核心的信念(想法)。先放結果圖。
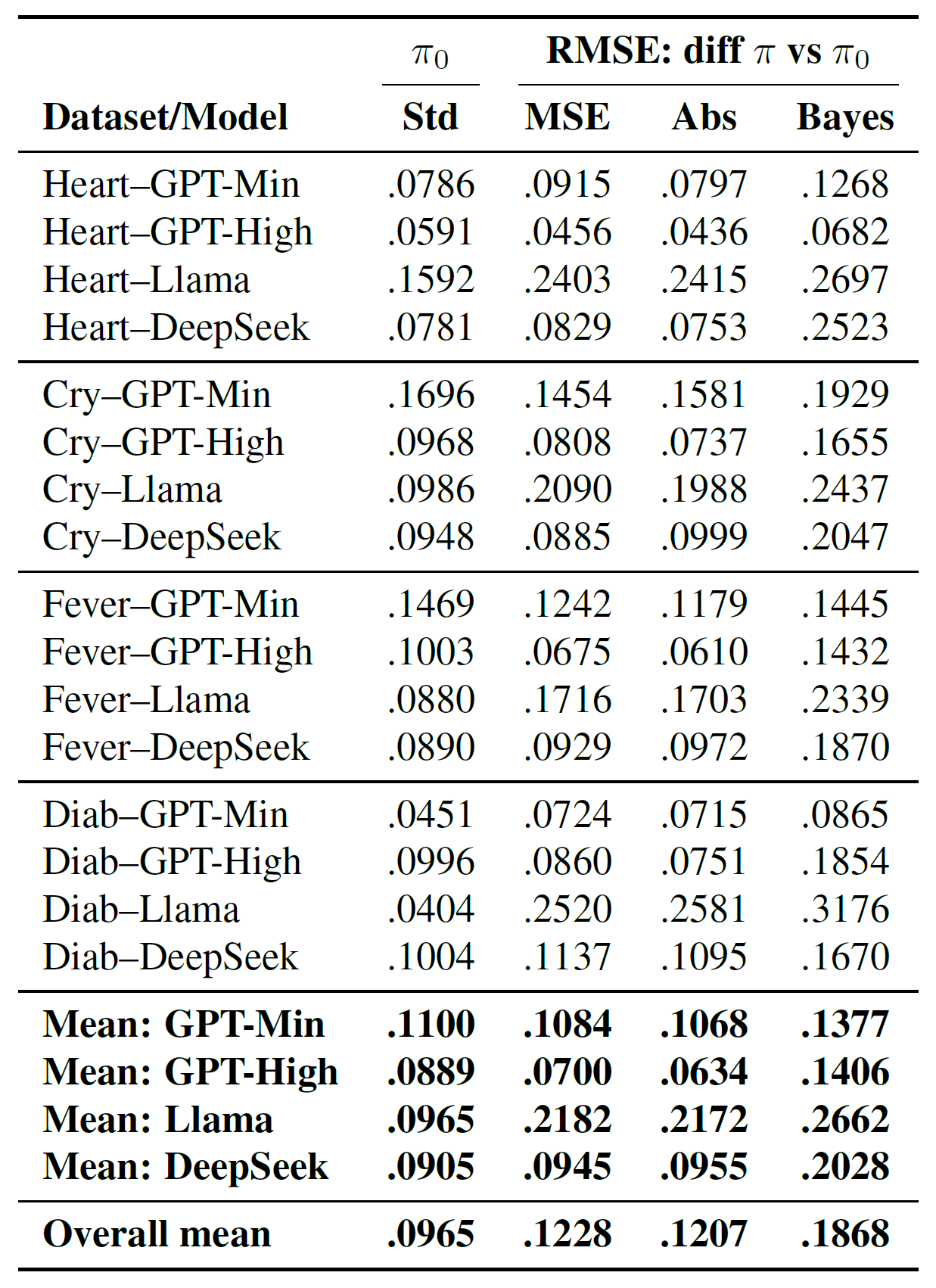
指的是基礎提問。實驗中,作者換了三種評估函數:MSE、Abs和Bayes。為了確定基礎提問本身獲得回答的範圍區間,利用同樣的基礎提問提示詞重複多次詢問,建立一個標準差區間,再用各評估函數問到的機率,和重複基礎提問獲得的平均機率,計算RMSE,對照自身多次提問的標準差,看是不是差不多。這個評估的結果顯示,各模型除了Llama,對於改變評估方式,不太會影響其回答。其中,Bayes算是比較有變化的,作者認為可能跟提示詞中有「你是貝葉斯推理者」這樣的角色扮演成分有關係。
評估四、迭帶期望法則(模型內部條件機率的自洽性)
把一開始基礎提問得到的機率,和加上各種條件之後得到的機率的總和相減,得到。將它除以基礎提問多次得到的中位數機率做正規化(),以評估誤差的嚴重度。圖六為結果。
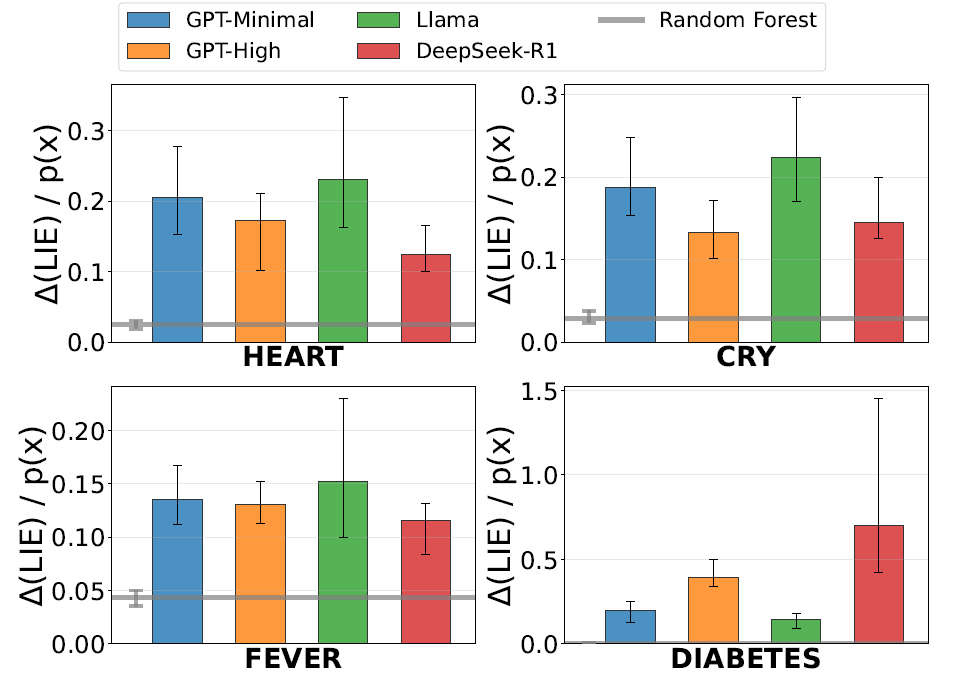
實驗中用一個使用資料集訓練的隨機森林(Random forest)當作基準,這是為了配合資料集高維度特徵,能找到最貼近LIE的方法。從圖六也可以看出,隨機森林的基礎線確實最低。而參與實驗的所有模型,在所有資料集都達不到條件機率的自洽性。這也說明即使在前三個評估表現好的模型,也不保證機率模型的運作的連貫性。
結論
我覺得這篇研究有趣的地方有二:一是討論模型是否基於給出的答案作判斷,二是驗證條件機率的完整性。當然,他使用醫學資料來做大語言模型的行為判斷這點,也是個亮點。
從實驗結果來看,能歸納出來的結果就是:不要相信模型給的機率,與其詢問模型機率,不如請它直接判斷。因為給出來的機率有機會和他採取的行動(即判斷)不同,甚至相反,而又不能符合條件機率的完整性,這讓模型輸出單純的機率變得很不可靠。然而,模型的判斷不受提問方式的影響,在某方面來說,其實提示詞的重要性可能沒想像中高(但角色提示似乎確實有效?)
同時,模型應該存在部分背景知識,這些知識會讓它在採取行動時,不只參考提供給它的資訊。我們知道,它具備查詢能力。帶來的資訊量可能比提供的還多。
當然,這些都是純粹就使用模型的角度來說。最根本的問題還是:模型有形成信念嗎?他有想法嗎?這個爭辯並沒有因為這篇文章獲得解答。我也覺得兩方的支持者都提出很多有趣的觀點,而選擇哪個相信,似乎比較接近信仰,至少目前不像純數學可以論證的。
文獻參考
[1] Do LLMs act like rational agents? Measuring Belief Coherence in Probabilistic Decision Making. Yamin et al. arXiv:2602.06286v1