強化學習簡介(3)--價值和策略迭代
這篇要延續前一篇,利用最佳價值來尋找策略的方式來找到任務最佳解。
首先引入動態規劃(dynamic programming)的觀念。其目的是將問題拆解為多個子問題,並利用找出子問題的最佳解來組合全局最佳解。貝爾曼函數因為每次都只找到當下狀態的最佳解,因此適合使用動態規劃的方式尋找最佳解。利用動態規畫尋找最佳策略的作法有兩種:價值迭代和策略迭代。
價值迭代
求解馬可夫決策過程中的最佳價值函數。
步驟
迭代更新價值函數和Q函數,直到價值函數收斂。使用貝爾曼備份來更新。
- 初始化:將價值函數初始化為任意值。
- 迭代更新:依據貝爾曼函數更新所有狀態的價值函數
。
- 收斂檢查:觀察價值函數與迭代前的價值函數之差異是否小於公差(),若有則終止迭代,否則重複迭代。
- 根據價值函數提取最佳策略:集合各狀態能獲取最佳Q值,成為最佳策略。
舉例
有A、B、C三狀態,及a=0、a=1兩種行動。折扣因子為0.1。各狀態轉換機率、獲得獎勵依行動畫圖如下:
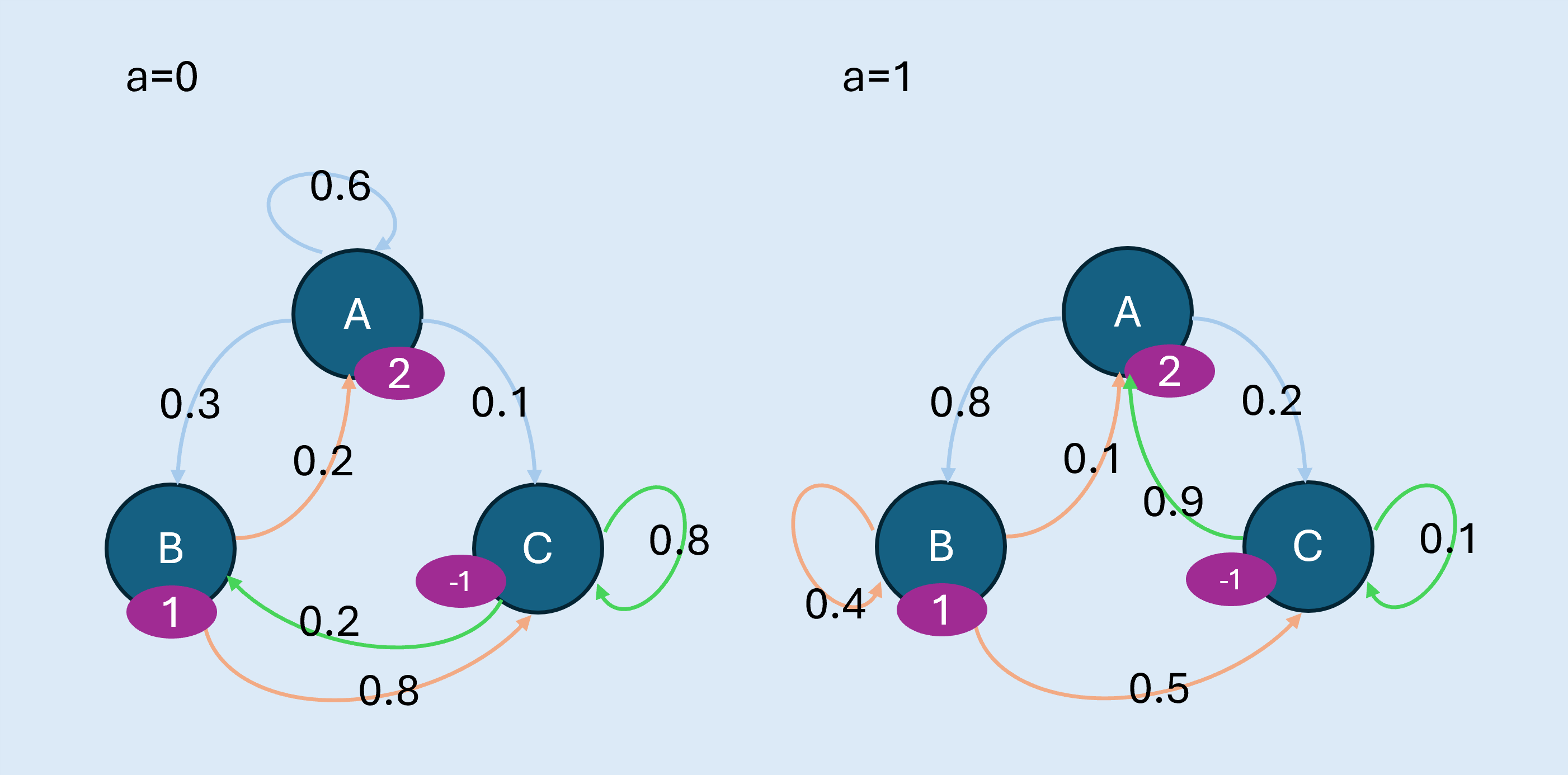
- 初始化:這裡將初始值設為0。
- 第一次迭代:計算各狀態的Q值,並填入Q表。
Q(B,0)=0.2[2+0.1(0)]+0[1+0.1(0)]+0.8[(-1)+0.1(0)]=0.4+0-0.8=-0.4
Q(B,1)= 0.1[2+0.1(0)]+0.4[1+0.1(0)]+0.5[(-1)+0.1(0)]=0.2+0.4-0.5=0.1
Q(C,0)=0+0.2-0.8=-0.6
Q(C,1)=1.8+0-0.1=1.7
- 更新價值:V(A)=1.4, V(B)=0.1, V(C)=1.7。
- 和原本價值相比:|1.4-0|+|0.1-0|+|1.7-0|=3.2,預設=0.01是超過的,所以必須繼續迭代,並更新價值表。
- 第二次迭代:
- 更新價值:V(A)=1.504, V(B)=0.203, V(C)=1.843。
- 和原本價值相比:|1.504-1.4|+|0.203-0.1|+|1.843-1.7|=0.104+0.103+0.143=0.35,還是超過0.01,必須更新價值表並進行下一次迭代,但落差比起第一次已經縮小很多。
- 第三輪迭代,V(A)=1.515, V(B)=0.215, V(C)=1.854,和原本價值相比為0.011+0.012+0.011=0.034,還是超過。
- 第四次迭代,V(A)=1.516, V(B)=0.216, V(C)=1.855,和原本價值相比為0.003,小於\epsilon,故將V表更新,迭代結束。現在V表為最佳價值。
- 計算Q值:計算方式和前面一樣,等於再跑一次迭代,但把V值代入最佳V值。
Q(A,0)=1.504
Q(A,1)=0.654
Q(B,0)= -0.221
Q(B,1)=0.217
Q(C,0)=-0.447
Q(C,1)=1.855 - ,故。最佳策略:狀態A採取行動0,狀態B採取行動1,狀態C採取行動1。
策略迭代
和價值迭代一樣用於求解最佳價值和最佳策略,一樣更新價值函數值到收斂,也一樣使用貝爾曼備份來更新價值函數,主要差異在於策略改進。
步驟
- 策略初始化:將策略及價值函數初始化
- 策略評估:分兩部分
-- 計算策略價值:以目前的策略,迭代更新價值函數。行動本身的隨機性被排除,只剩環境隨機性
-- 收斂檢查:看價值之間的差異是否小於公差(),若仍大於則反覆迭代,若已小於則可終止迭代 - 策略改進:
-- 提取策略:利用剛剛得到各狀態的V值,計算Q值,這裡所有行動都要算。然後依據收斂的價值提取策略(根據最佳Q值選定各狀態的行動組成策略)
-- 收斂檢查:檢查此策略與當前策略是否一致,或小於公差(),若無,則更新策略,回到策略評估流程,若有,則完成演算法,得到最佳策略
舉例
利用上方圖1.的例子來說明。
- 策略初始化:將策略及價值函數初始化。這裡將策略設為(0,0,0),表示初始策略在三個狀態下都採取a=0的行動。價值也初始化為0。
- 策略評估:計算各狀態,行動a=0的V值。不用算a=1的,因為當前策略已經指定行動。
,
- 收斂檢查:|1.4-0|+|-0.4-0|+|-0.6-0|=2.4>0.01,未收斂,更新V表進行第二次迭代
- 第二次迭代:,此時落差0.066+0.02+0.056=0.142仍超過,故要進行第三次迭代
- 第三次迭代:三個值依序為1.469, -0.423, -0.661,落差為0.011剛好超過一點,進行第四次迭代。最後在第四次迭代,三個值為1.469, -0.424, -0.661,落差為0.001,已收斂,更新V表如下
- 計算Q值:
V一樣,但機率和當前獎勵要切到a=1。以此類推,Q(B,0)=-0.424, Q(B,1)=0.065, Q(C,0)=-0.661, Q(C,1)=1.826,更新Q表
- 提取策略:,所以,,和原始策略不一致,所以要重新進行策略評估
- 重新回到1.,進行第二輪策略評估。重設價值為0,但策略換成(0,1,1)來迭代V值。
- 第一次迭代:,,,落差為0.32,需再進行迭代。
- 到第四次迭代時收斂,此時V(A)=1.516, V(B)=0.216, V(C)=1.855,更新V表
- 策略改進,計算Q值:Q(A,0)=1.515,Q(A,1)=0.553,Q(B,0)=-0.221, Q(B,1)=0.217, Q(C,0)=-0.477, Q(C,1)=1.855,更新Q表
- 提取策略:,,,最佳策略為(0,1,1),迭代結束。